2022N.GAME網(wǎng)易游戲開發(fā)者峰會于「4月18日-4月21日」舉辦,本屆峰會圍繞全新主題“未來已來 THE FUTURE IS NOW”,共設(shè)置創(chuàng)意趨勢場、技術(shù)驅(qū)動場、藝術(shù)打磨場以及價值探索場四個場次,邀請了20位海內(nèi)外重磅嘉賓共享行業(yè)研發(fā)經(jīng)驗、前沿研究成果和未來發(fā)展趨勢。

今天的分享來自技術(shù)驅(qū)動場的嘉賓陳康,他是網(wǎng)易互娛AI Lab的技術(shù)經(jīng)理。以下是嘉賓分享實錄(部分刪減與調(diào)整):
大家好,我是來自網(wǎng)易互娛AI Lab的陳康,目前負責互娛AI Lab滬杭團隊,圖形學(xué)、3D視覺和語音方向的技術(shù)研發(fā)和落地,很高興有這個機會給大家分享一下我們部門從17年底成立到現(xiàn)在,在基于AI的美術(shù)資源生產(chǎn)方面做過的一些嘗試。

首先,什么是美術(shù)資源呢?
這在游戲行業(yè)其實是一個專有名詞,也叫美術(shù)資產(chǎn)。我們這邊以一夢江湖和王牌競速兩款游戲為例,一個偏古風的、一個偏現(xiàn)代的,藝術(shù)風格上是有明顯差異。但共同點是你在畫面里看到的所有東西,比如說人物、人物上看到的衣服、遠處的建筑、植物、車輛、甚至界面上的這些按鈕圖標,其實都是美術(shù)同學(xué)在DCC軟件或者游戲引擎中制作出來的,所以這些東西都屬于美術(shù)資產(chǎn)。

游戲行業(yè)發(fā)展到今天,在美術(shù)資產(chǎn)制作方面,已經(jīng)形成了一套非常成熟的工業(yè)化、流水線生產(chǎn)的解決方案。
我們以我們部門的虛擬技術(shù)代言人,同時也是峰會的虛擬主持人i.F. 為例,給大家簡單介紹一下常見美術(shù)資產(chǎn)的制作過程。
假設(shè)你作為一名策劃同學(xué),想要美術(shù)幫你制作一個這樣的角色,你會怎么跟他表達需求呢?你可能會說你想要活潑可愛的二次元妹子,處于青春期的年齡段、可能性格有點呆萌……但這種描述其實都是很主觀、抽象的描述,都是二次元,陰陽師那種二次元和原神那種二次元是有很大差異的。
基于這種模糊的描述,美術(shù)是沒法直接制作三維模型的,因為在這過程中肯定需要不停的迭代需求,甚至有可能推翻重做,所以在三維模型環(huán)節(jié)進行這種角色設(shè)計層面的迭代,成本是非常高的。
所以策劃的需求一般會先給到原畫師,原畫師會首先把這些抽象的描述轉(zhuǎn)化成具體的形象,所有形象設(shè)計層面的修改和迭代都是在原畫階段完成的。

這邊展示的就是i.F.的角色原畫,當然在設(shè)計過程中,原畫師肯定會融入的自己理解,提出一些修改。因為在這個領(lǐng)域美術(shù)要比策劃專業(yè)的多,比如IF這個形象,頭上帶的這個像兔子耳朵一樣的耳機,就是原畫同學(xué)自己設(shè)計出來的。我們的需求是制作一個青春可愛的技術(shù)代言人,這個耳機可以在保持角色可愛風格的同時,體現(xiàn)出一定科技元素。
角色的原畫設(shè)定圖完善之后,就會進入模型環(huán)節(jié),模型師會參考這個形象制作三維模型和對應(yīng)的材質(zhì)貼圖。這邊對模型師的要求就是,制作完成的模型和貼圖放到游戲引擎之后,最大程度能夠還原原畫設(shè)計的形象。如果是靜態(tài)物體的話,一般這一步做完就結(jié)束了,后面就直接交給場景編輯師在游戲引擎中搭建游戲場景就可以了。

但是游戲角色的話其實他是要能動起來的,所以模型制作完成后,還要交給綁定師架設(shè)骨骼、蒙皮、一些變形體。然后制作綁定控制器,也就是角色身上的這些奇怪的線圈和右邊的面板,通過操縱這些東西,就可以驅(qū)動角色做出一些對應(yīng)的動作,綁定好的角色會交給動畫師,動畫師會采用動作捕捉,或者手動設(shè)定關(guān)鍵幀的方式制作動畫資源。

整個美術(shù)資產(chǎn)的生產(chǎn)過程,類似一條工業(yè)流水線,一環(huán)套一環(huán)。尤其是在玩家越來越挑剔、游戲行業(yè)越來越激烈的情況下,這塊的開銷一直是游戲研發(fā)成本的大頭。像是現(xiàn)在的3A大作,如果不支持開放世界,已經(jīng)不好意思說自己是本世代游戲了。
開放世界是怎么打造開放感的?簡單來說就是生產(chǎn)內(nèi)容。比如《刺客信條》《孤島驚魂》這種級別的游戲,地圖動不動就幾十平方公里,這種規(guī)模按傳統(tǒng)方式制作已經(jīng)不現(xiàn)實了。所以如今的游戲開發(fā)會最大程度利用程序化手段制作美術(shù)資源。
而我們的工作,本質(zhì)上就是要在程序化生產(chǎn)這條主線下,引入一些AI技術(shù)手段,從而實現(xiàn)一些傳統(tǒng)方案無法做到的效果。下面我來介紹一下我們在原畫、模型和動畫三個方面做過的一些嘗試。
AI在原畫方面的應(yīng)用
在原畫方面,我們做了兩個輔助創(chuàng)作的工具。第一個工具用于二次元角色線稿的自動上色,并且可以生成多套不同的上色方案,主要作用是在設(shè)計二次元形象時,為美術(shù)提供一些色彩搭配的靈感。

第二個工具用于人臉的生成和編輯,它可以基于美術(shù)繪制的人臉線稿生成真實人臉照片,并且允許編輯人臉的一些屬性。這里展示的,是修改人臉年齡后的結(jié)果。

由于互聯(lián)網(wǎng)上的人臉數(shù)據(jù)非常豐富,人臉結(jié)構(gòu)也相對比較簡單,所以目前這個工具可以生成非常高清的人臉照片。在設(shè)計一些寫實類角色時,美術(shù)可以參考這些素材進行二次創(chuàng)作。
當然,我知道很多同學(xué)對AI在原畫方面的應(yīng)用還有更高的期待。比如說利用GAN或風格遷移等技術(shù)直接生成場景原畫,這也是AI技術(shù)最早出圈的一批應(yīng)用。不過目前想要落地還稍微有點困難,倒不是說技術(shù)本身有什么問題,主要是因為游戲原畫設(shè)計追求的不一定是真實,更多是一種特定藝術(shù)風格下的視覺表達。
我們隨便找一幅游戲畫面對比一下,就會發(fā)現(xiàn)這種圖片跟日常照片有明顯區(qū)別。在當前的數(shù)據(jù)條件下,想生成這種級別的AI模型還比較困難。所以如何讓AI在原畫設(shè)計方面發(fā)揮更多的作用,也是我們未來的重點方向之一。

人臉模型
在模型方面,我們的主要工作圍繞在人臉模型上。首先簡單介紹一個基礎(chǔ)設(shè)施——三維參數(shù)化人臉模型,這是一個基于大量三維掃描得到的三維人臉數(shù)據(jù)制作出來的雙線性模型,有臉型和表情兩個維度,簡單說就是任意給定一組臉型參數(shù)、一組表情參數(shù),就會得到一個對應(yīng)參數(shù)下的三維人頭模型。
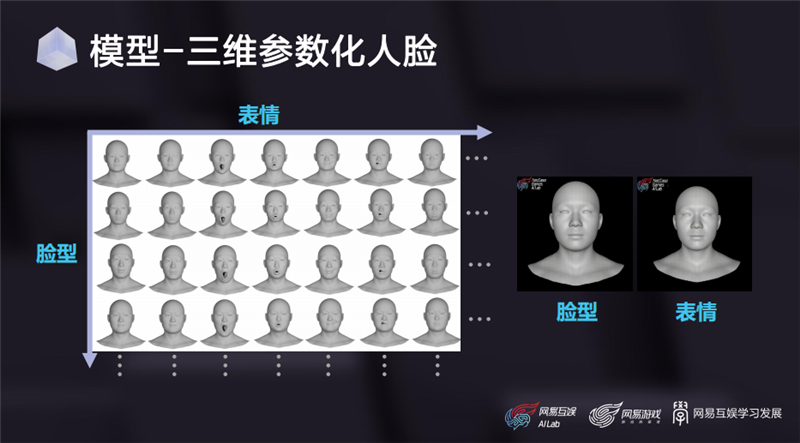
在2018年,我們自己掃描并制作了一套高質(zhì)量的三維參數(shù)化人臉。當時一共采集了500個中國人的數(shù)據(jù),其中男女各占一半,年齡段涵蓋10-60歲,每個人掃描了7套表情,相當于一共采集了3500個人頭。

我相信很多從事相關(guān)研究的同學(xué)對這個模型概念非常熟悉,這是由一篇1999年的SIGRAPH論文提出的概念,專業(yè)名稱叫3DMM,目前學(xué)術(shù)界有一些很出名的開源3DMM數(shù)據(jù)。那我們?yōu)槭裁床恢苯佑眠@種開源模型呢?主要有三方面原因:
首先是版權(quán)問題,我們希望這套技術(shù)真的能在游戲產(chǎn)品中用起來;
其次是精度問題,這些開源模型的精度距離實際游戲的標準還有不小的差距,我們早期做實驗也會使用這些模型,但是美術(shù)會對質(zhì)量非常嫌棄。所以我們自己采集時,每一個人頭后續(xù)都人工精修過;
最后是人種問題,這些開源模型一般都是歐美機構(gòu)發(fā)布的,他們采集的對象主要是歐美的高加索人種。這種明顯的高鼻梁、深眼窩特點,一看就不是亞洲人,所以我們果斷決定自己制作一套。

在AI領(lǐng)域,參數(shù)化人臉的主要作用是提供關(guān)于人臉的三維形狀先驗,所以制作好的參數(shù)化三維人臉模型可以用于從二維照片中重建三維人臉模型。我們這套參數(shù)化人臉模型,在東亞人臉照片上取得了非常好的重建效果。

當然,由于單視角照片會在深度方面存在缺失,很難還原類似鼻梁高度、眼窩這方面的特征,所以我們也開發(fā)了一套多視角的重建算法。如果條件允許,可以拍攝演員的多張照片進行重建。大家可以對比一下——右邊多視角的重建結(jié)果對演員鼻子形狀的還原程度,要比單視角高非常多。

除了從照片中重建三維模型,這套參數(shù)化人臉還有一個更重要的應(yīng)用,就是為游戲批量生成人頭模型。如果游戲的人頭資源標準跟我們庫里的標準一致,就可以直接在參數(shù)化人臉模型的參數(shù)空間采樣,把采樣模型給到游戲項目使用。
當然,這種情況一般不太多。因為每個游戲都會有自己特定的需求,有些游戲的角色甚至都不是傳統(tǒng)意義上的人頭。所以更常見的一種生成方式,是對項目組的模型進行自動批量變形。簡單來說,就是把我們生成的模型相對于平均臉的變化,遷移到項目組的模型上面。這種遷移的變化可以是表情,可以是臉型,并且所有變形都可以用項目規(guī)定的骨骼蒙皮進行表達。

這是一組我們生成的結(jié)果,最左邊是項目組提供給我們的角色模型。我們可以根據(jù)這個模型自動批量生成一批風格相同,但臉型和五官有明顯區(qū)別的模型,并且每個模型都可以生成一套表情。也就是說,項目組只需要做一個靜態(tài)模型,我們就能自動批量生成很多綁定好的模型。這對追求千人千面的開放世界游戲非常有價值,可以以非常低的成本讓游戲里的每個NPC看起來都不一樣。

這是我們對兩個Metahuman模型變形后的效果,可以看到我們生成人頭模型與原始的資源標準是完全兼容的。而且以這個變形質(zhì)量生成的模型,作為實際游戲的頭模也綽綽有余,大家要知道,像Metahuman這種級別的模型,一個頭的成本,保守一點計算都要小幾十萬人民幣,所以這個技術(shù)是非常有價值的。
為了進一步豐富我們的三維人頭數(shù)據(jù),我們也在杭州園區(qū)設(shè)計和搭建了一套三維掃描實驗室。左邊是我們的設(shè)計圖,右邊是搭建完成后的實物。這是一個正20面體,一共包含53臺單反和150組定制LED燈光。后續(xù)我們還會在網(wǎng)易的廣州和上海園區(qū),分別搭建一套更大的,可以掃描全身的設(shè)備。

三維掃描的原理其實非常簡單——利用攝影測量算法,從多視角照片中計算人頭的三維點云。這是我們系統(tǒng)掃描的一組樣例,這個精度可以對標國內(nèi)外一線掃描服務(wù)供應(yīng)商。

這是基于我們掃描流程制作的一組表情基的效果,可以看到,掃描模型對演員面部細節(jié)的還原程度是非常高的。
這套設(shè)備150組定制的LED燈光,也是我們花很高成本定做的。每一盞燈的開關(guān)和亮度可以獨立控制,每一組燈光包含三個燈頭,分別安裝了一個普通無偏振的UV鏡和兩個偏振鏡。這兩個偏振鏡相對于相機上安裝的偏振鏡方向一個是平行的,一個是垂直的。

了解攝影的同學(xué)應(yīng)該很熟悉偏振鏡的用法,這是一種很常用的UV鏡,主要用于非金屬物體表面一些不必要的反射光,可以還原物體本身的顏色。

偏振鏡的原理大家在中學(xué)物理就學(xué)過——光既是粒子、也是一種電磁波,它的振動方向與傳播方向是垂直的,這種類型的波叫橫波,所有的橫波都具有偏振現(xiàn)象。簡單來講,光的偏振方向與偏振鏡方向平行,那么所有能量都會通過;如果是垂直的,那么所有能量都會被過濾。
基于這個原理,我們只要給掃描物體拍攝4組平行偏振光和4組交叉偏振光的燈光下照片,就可以算出物體表面的材質(zhì),也就是漫反射、高光和法線的信息。每組照片都要首先打開所有燈光,然后是按照燈光在三維空間的坐標值遞減亮度,XYZ三個方向分別可以產(chǎn)生一組燈光。

目前這套設(shè)備我們剛剛搭建完成,在人臉材質(zhì)掃描方面也是剛剛起步,后續(xù)我們會逐漸加大投入。
近幾年工作的重心:動畫
最后是動畫部分,這是我們這幾年工作的重心。前面提到,游戲研發(fā)總成本的大頭一般是美術(shù)資產(chǎn),那么美術(shù)資產(chǎn)成本的大頭一般就是動畫。因為原畫、模型雖然也很貴,但大部分屬于一次性開銷,而動畫則需要配合劇情持續(xù)產(chǎn)出,且高質(zhì)量動畫一分鐘的制作成本很輕松就可以過萬。
在這方面,我們首先在光學(xué)動捕數(shù)據(jù)的清洗方面做了一些工作。光學(xué)動捕會在緊身動捕服表面設(shè)置很多標記點,通過多視角紅外相機跟蹤這些點的坐標,并算出人體骨骼的旋轉(zhuǎn)、平移信息。當然,這些數(shù)據(jù)不可避免會有錯誤,所以會有專人負責清洗標記點。
資深的動捕美術(shù)直接看標記點的軌跡曲線,就能知道出現(xiàn)了什么錯誤、怎么修改,這也是目前動捕工作流中主要的人工工作量。
2018年,育碧提出了一種通過AI模型來取代這個過程的算法,發(fā)表在了SIGGRAPH上;2019年,網(wǎng)易投資了一家法國3A游戲工作室Quantic Dream,也就是《底特律:變?nèi)恕返难邪l(fā)商。當時我們開始有一些技術(shù)合作,他們提出需求后,我們跟進了相關(guān)研究。一年多之后,我們找到了一種精度更高的解決方案,也發(fā)表在了SIGGRAPH上。

目前我們已經(jīng)把這套算法,以vicon軟件的插件形式部署在了網(wǎng)易互娛和Quantic Dream的動捕工作流中。這里是一個例子:這是原始含噪音的標記點,閃來閃去的就是局部噪音,留在原地的就是跟丟的那些點,這是暫時調(diào)用我們算法得到的清洗結(jié)果。
接下來介紹幾個我們部門落地最多的項目:首先是一套基于普通單目攝像頭的輕量級面部動捕系統(tǒng),基本原理就是利用前面的三維參數(shù)化人臉模型,對視頻中演員的臉型、表情頭部姿態(tài)進行回歸,把回歸得到的系數(shù)重定向到游戲角色上。

當然,我們也會配合一些CV檢測和識別模型,加強算法對眨眼、視線、舌頭和整體情緒的捕捉精度。這個項目我們從2018年開始做,前前后后差不多有十位同事參與。其中所有算法模塊都是我們自己開發(fā),打磨到現(xiàn)在已經(jīng)是一套非常成熟的in-house面部動捕解決方案。
圍繞這套算法,我們還打造了一整套工具鏈,有實時的動捕預(yù)覽工具,有針對動捕結(jié)果進行離線調(diào)整和編輯的工具,還有Maya/Max里的動捕數(shù)據(jù)重定向插件。另外為了方便項目組接入面部動捕系統(tǒng),我們還開發(fā)了一套專門適配自家算法的面部自動綁定插件。此外,核心算法我們還打包了全平臺的SDK,在iPhones 6s以上的機器,可以做到單核單線程實時。

這套系統(tǒng)在游戲里有非常多的應(yīng)用場景,首先就是輔助動畫師制作正式的游戲動畫資源。相比于傳統(tǒng)一幀一幀手key,采用動捕方案的制作效率有明顯優(yōu)勢。而且只要演員表演到位,效果跟美術(shù)手key幾乎看不出來區(qū)別;
其次,它可以給營銷同學(xué)快速產(chǎn)出一些面部動畫素材,營銷場景的特點是精度要求沒那么高,但時效性要求很高,因為慢了就跟不上實時熱點了。我們這種輕量級方案非常適合這種場景,比如某段短視頻火了,用這套工具可以快速產(chǎn)出面部動畫素材;
另外,因為我們的算法會提供全平臺SDK,所以也可以打包在游戲客戶端里,給玩家提供一些UGC玩法。比如我們在《一夢江湖》里上線的顏藝系統(tǒng),可以讓玩家錄制自己的表情動畫。右上是我在B站上找到的一個視頻——玩家錄制的打哈欠動畫;

最后,這套算法還可以支持一些虛擬主播場景,比如《第五人格》禿禿杯電競比賽的虛擬解說、
云音樂look直播的虛擬主播,用的都是我們這套技術(shù)。
另外,我們還配合高精度三維掃描設(shè)備,測試了面部動捕算法在超寫實模型上的效果。我們雇了一位國外模特掃描模型,用模特錄制的視頻來驅(qū)動他對應(yīng)的角色,以便更好地對比表情還原度。

還有另外一組效果,這位模特是我們部門的一位同事。從效果上可以看到,不管是掃描重建還是面部捕捉,我們的技術(shù)都足夠支持這種高精度場景。
跟面部動捕類似,我們也做了一套輕量級基于普通攝像頭的身體動捕系統(tǒng),支持單視角、多視角輸入,原理類似于前面的面部捕捉,同樣也會配合一些CV模型提升優(yōu)化結(jié)果的合理性。這個項目我們打磨了兩年時間,目前效果和穩(wěn)定性都相當不錯。

這是在冬奧結(jié)束之后,我們用這項技術(shù)為《哈利波特:魔法覺醒》項目制作的視頻,當時很快就沖上了微博熱搜。如果按傳統(tǒng)制作方式,這種營銷策劃案是不太可能實現(xiàn)的,因為要找到能還原這套動作的演員,還要約演員和動捕棚的檔期,一套下來沒有六位數(shù)開銷和一個多月制作周期的話,是很難完成的。但是用這套AI方案,成本就可以忽略不計。

這是更早時候,我們與《大話西游》項目組合作的一段視頻。當時請了B站舞蹈區(qū)的一位知名Up主,用三部手機錄了這套舞蹈動作,用我們的動捕算法得出數(shù)據(jù),重定向到《大話西游》的角色上。

另外,我們還為《明日之后》項目組制作了一些動畫素材,只用了一個單目攝像頭捕捉身體和面部動作,并且只要拍得足夠清晰,手指動作也可以準確捕捉。

除了基于視頻輸入以外,我們還做了基于音頻輸入生成動畫的技術(shù),比如從語音輸入生成角色面部和肢體動畫的工具鏈。這項技術(shù)我們在2018年就已經(jīng)應(yīng)用于不少游戲,當時做得還比較簡單,只支持口型和幾種簡單的基礎(chǔ)情緒。后來我們做了持續(xù)的基礎(chǔ)升級和迭代,增加了語音驅(qū)動頭動、眼動、手動、面部微表情,還有肢體動作等等。
另一個從音頻輸入生成動畫的工作,是基于音樂生成舞蹈動作。這項工作我們從2018年開始研究,經(jīng)過幾年迭代最終形成了一套方案,詳細的技術(shù)方案在論文里有介紹,這里主要展示實際落地效果:首先是二次元女團舞;

這是一段韓舞的動畫,也是網(wǎng)易CC直播年度盛典的開場舞蹈。

另外,我們也會用一些網(wǎng)絡(luò)熱門歌曲合成舞蹈。去年圣誕節(jié)時,我們用虛擬偶像I.F.制作的B站互動視頻,其中所有動畫都是通過AI技術(shù)生成的。目前這套AI動畫的解決方案已經(jīng)相當成熟,在內(nèi)部經(jīng)過了大量項目的驗證,目前也在持續(xù)為網(wǎng)易的各個項目組輸出動作資源。
數(shù)據(jù)是AI的核心
最后簡單總結(jié)一下,從前面的介紹中大家可以發(fā)現(xiàn),AI技術(shù)對程序化美術(shù)資源生成能產(chǎn)生明顯的促進作用。而且根據(jù)我們的實踐經(jīng)驗,在人臉、人體的模型和動畫方面,它甚至可以在一定程度上取代一些初級執(zhí)行向美術(shù)的工作。而且利用我們的AI方案,普遍可以比傳統(tǒng)方案提升5-10倍的制作效率。
但目前想讓AI從事一些更高級的工作還比較困難。主要難點是高質(zhì)量數(shù)據(jù)比較稀缺,大家都知道數(shù)據(jù)是AI的核心,AI模型有多少能力,很大程度上取決于人給了模型多少有價值的數(shù)據(jù)。但是游戲資產(chǎn)的獲取門檻還是很高的,這跟照片、語音、文字這種所有人日常都在生產(chǎn)的數(shù)據(jù)不太一樣。
比如在某個景點看到一個很有特色的雕塑,絕大部分人的反應(yīng)可能是掏出手機,拍一張照片記錄一下,但幾乎不會有人掏出電腦現(xiàn)場建個模。當然,隨著技術(shù)進步,游戲資源的制作門檻肯定會越來越低,而且像元宇宙這樣的熱門應(yīng)用場景,本身也要求游戲廠商讓廣大玩家參與到虛擬世界的內(nèi)容創(chuàng)造過程中來。
所以我相信,隨著數(shù)據(jù)的持續(xù)積累,未來AI技術(shù)也有可能從事一些更高級的工作,這也是我們的努力方向,謝謝大家。
N.GAME是由網(wǎng)易互娛學(xué)習(xí)發(fā)展舉辦的一年一度行業(yè)交流盛事,至今已成功舉辦七屆。本屆主題為“未來已來The Future is Now”,邀請了20位海內(nèi)外重磅嘉賓、高校學(xué)者匯聚一堂,共享行業(yè)研發(fā)經(jīng)驗、前沿研究成果和未來發(fā)展趨勢。
點擊“閱讀原文”查看更多分享!