速途網8月4日訊(報道:喬志斌)今日,商湯科技SenseTime公布了以原創(chuàng)AI技術賦能新藥研發(fā)和精準醫(yī)學的多項最新重磅研究成果,覆蓋藥物發(fā)現(xiàn)、臨床前研究、臨床試驗、新藥上市后等多個藥物研發(fā)環(huán)節(jié),旨在通過AI技術加速新藥研究和上市流程,縮短新藥研發(fā)周期、降低藥品研發(fā)成本、提高新藥研發(fā)成功率。目前,相關成果已發(fā)表在《自然精準腫瘤學》(Nature Precision Oncology)、《生物信息學》(Bioinformatics)、國際人工智能聯(lián)合會議(IJCAI)等國際頂尖期刊及會議上,同時開源相關代碼,為醫(yī)藥行業(yè)的基礎研究和創(chuàng)新提供前沿的突破思路。
商湯科技副總裁、研究院副院長張少霆表示,“新藥研發(fā)是關系著人類生命健康的事業(yè),是一項艱巨且風險極高的工作,需要多學科之間的相互合作。依托商湯科技沉淀多年的原創(chuàng)技術能力,商湯智慧健康首次以AI賦能新藥研發(fā),希望全面深入發(fā)掘化合物、蛋白、細胞系和臨床大數(shù)據(jù)中的潛在規(guī)律,為加速新藥研發(fā)進程提供精準的依據(jù),并逐步覆蓋新藥研發(fā)多個環(huán)節(jié),幫助藥企和相關研發(fā)機構降低藥物研發(fā)風險、提高效益,加速新藥的研發(fā)和落地,為提升人類健康水平貢獻力量。”

藥物發(fā)現(xiàn):自主學習蛋白相互作用及其分類,輔助藥物作用靶點定位
作為構成細胞的基本有機物,蛋白質分子及其之間的相互作用是細胞實現(xiàn)各項復雜功能的基礎。因此,基于蛋白相互作用(protein-protein interactions,簡稱PPI)構建蛋白關系網絡,可幫助分析疾病發(fā)生時的分子作用機制,從而幫助研究人員發(fā)現(xiàn)和理解藥物作用靶點,推動新藥研發(fā)。然而,以實驗研究為主的傳統(tǒng)PPI研究方法不僅耗時長,且難以有效分析PPI的具體分類。通過計算機模擬雖然可以快速為實驗室研究提供候選PPI、加速實驗效率,但是現(xiàn)有方法在遇到訓練集中未包含的蛋白數(shù)據(jù)時仍會出現(xiàn)性能損失,不能很好地泛化到未知的蛋白及PPI。這也對不斷發(fā)現(xiàn)的新蛋白質及其PPI、以及由此產生的潛在新靶點的分析提出了巨大挑戰(zhàn)。
商湯智慧健康團隊基于大量研究,在發(fā)布于IJCAI的《Learning Unknown from Correlations: Graph Neural Network for Inter-novel-protein Interaction Prediction》一文中提出了一種新的衡量指標(metrics),通過新的數(shù)據(jù)劃分方式,有效衡量模型在跨數(shù)據(jù)集、未知蛋白上的性能效果;同時還提出了一種新的建模方法(methodology),創(chuàng)新性地訓練了一套能夠學習蛋白間關聯(lián)關系的GNN(圖神經網絡)模型,實現(xiàn)了更穩(wěn)定的跨數(shù)據(jù)集表現(xiàn),從而實現(xiàn)了在未知PPI預測上的更優(yōu)性能。在行業(yè)通用的公開數(shù)據(jù)集上進行的跨數(shù)據(jù)集實驗中,商湯提出的新方法比現(xiàn)有方法的預測精度提高了36%。這兩大創(chuàng)新方案可以在新藥研發(fā)過程中,更好地幫助藥物作用靶點的發(fā)現(xiàn)、理解和選擇。

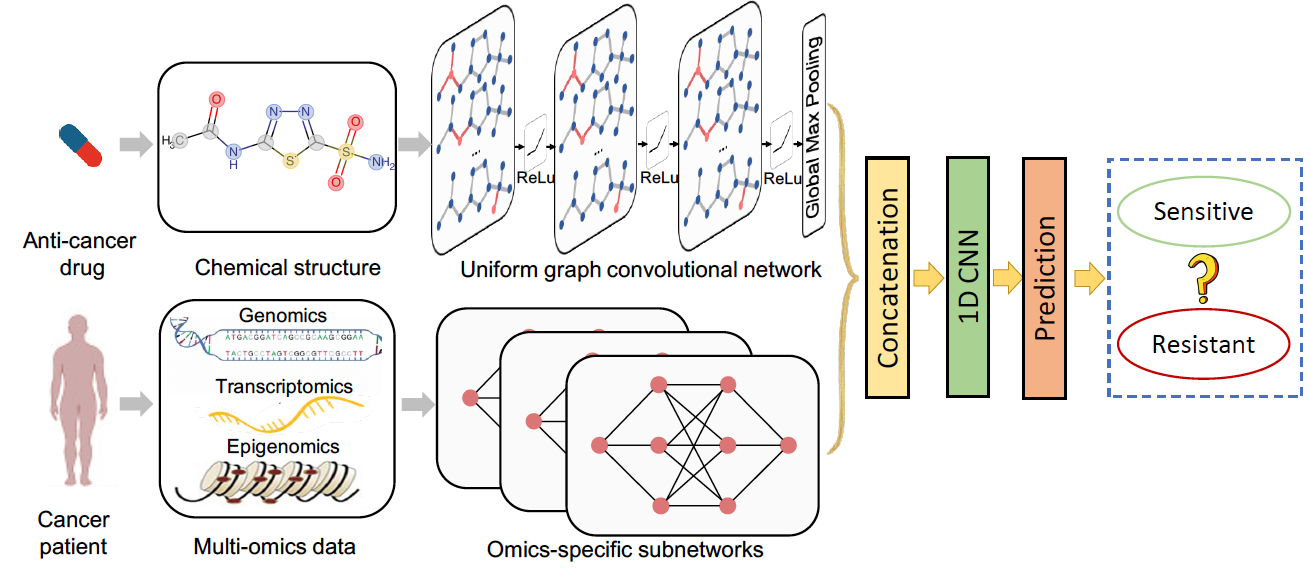
臨床前研究:高效細胞系數(shù)據(jù)處理,準確預測癌癥藥物反應
在新藥研發(fā)的臨床前實驗階段,對目標疾病的藥物反應進行準確預測是最重要、也最具挑戰(zhàn)性的任務,尤其是在癌癥治療領域。臨床前的實驗主要涉及使用計算模型和相關細胞組織在實驗室環(huán)境下的各項分析測試,為后續(xù)的人體臨床試驗墊定基礎。近年來,高通量基因測序技術的快速發(fā)展極大地推動了基于細胞系的癌癥藥物反應研究。然而,鑒于癌癥致病機理和藥物作用機制的復雜性,傳統(tǒng)方法仍不能有效抓取藥物的化學結構特征,并充分整合基因組、轉錄組等多種組學信息,限制了藥物反應預測準確率的進一步提升。
在發(fā)布于《生物信息學》的《DeepCDR: a hybrid graph convolutional network for predicting cancer drug response》研究中,商湯智慧健康團隊首次將GCN(圖卷積網絡)應用在癌癥藥物反應研究領域,提出了一種全新的混合圖卷積網絡模型DeepCDR。該模型可以自動挖掘和建立藥物化學結構特征,并能高效處理細胞系里的基因組學、轉錄組學、表觀基因組學等多元組學數(shù)據(jù),實現(xiàn)了對抗癌藥物反應的精準預測。在覆蓋238種藥物和561種細胞系的公開數(shù)據(jù)集上,該模型將預測精度指標(皮爾森相關系數(shù))從0.780提升到了0.923,為抗癌藥物在臨床前的實驗室環(huán)境下測試藥物敏感性、以及尋找腫瘤中調節(jié)藥物反應的新基因等提供了更加精準高效的研究工具。
臨床研究:基于病理圖像預測癌癥亞型,為降低亞型評估成本提供全新思路
隨著精準醫(yī)療技術的不斷發(fā)展,針對某種癌癥亞型或特定基因突變進行個性化治療的靶向藥物逐漸成為癌癥藥物治療的主要手段。新的抗癌藥物的研發(fā)也大都集中在這一領域。目前,為了確定患者所患的具體癌癥亞型,需要對患者的病灶組織進行基因測序,通過不同的基因突變情況進行分類,檢測的成本十分昂貴。
商湯智慧醫(yī)療團隊提出了一種全新的思路,利用深度學習技術挖掘數(shù)字病理圖像中的細胞特征信息,從而判斷組織的基因突變類別和相關生物信號通路信息。利用這一方法,商湯智慧醫(yī)療團隊成功的預測了肺癌、乳腺癌、肝癌中的多個重要基因突變特征,其中最好的預測性能指標(AUC)達到0.852。這一項研究為確定患者癌癥亞型提供了一種全新的思路和方法,未來可能將大幅度降低確定癌癥亞型的成本,從而造福癌癥患者。

新藥上市后:助推老藥新用,AI預測藥物新適應癥
鑒于新藥研發(fā)超長的研發(fā)周期和巨大的投入,上市后的老藥新用可以基于已知的化合物信息,以較低的成本和較短的周期進入臨床。然而,由于已上市的藥物數(shù)量相對有限,同時缺乏有效的藥物與新適應癥的篩選模型,導致目前市面上老藥新用的成功案例很少。只有做到充分挖掘藥物、疾病、蛋白之間的多維關系,才能為預測新適應癥提供更可靠的分析。
對此,商湯智慧健康團隊創(chuàng)造性地訓練了一套覆蓋藥物、疾病、蛋白多個領域間相互作用復雜關系的大規(guī)模GCN網絡模型,從而精準預測藥物與疾病之間的關系。該模型無需任何人工干預便可自主學習各關鍵信息間的關系,實現(xiàn)預測過程的全自動化以及對未知藥物適應癥的有效預測。在公開的repoDB小分子藥物重定向的數(shù)據(jù)集上,相比目前使用的機器學習方法公開的最好結果,此方法的預測結果取得了更好的成績,使相關科研團隊的預測結果性能指標(AUC)提升了8%(0.792→0.857)。目前,利用這項研究結果預測出的某種已經上市的心臟疾病藥物對于乳腺癌治療的潛在有效性,已經被臨床文獻所證實。未來,商湯智慧健康團隊希望利用這種方法,助力更高效的藥物新適應癥篩選過程,推動老藥新用的臨床進展。

回首過往,新冠疫情加速了全球醫(yī)藥行業(yè)的創(chuàng)新步伐。與此同時,國內今年來的藥品帶量采購、藥品管理法修訂等新政也助推了行業(yè)變革的到來,國內外各大藥企紛紛加大新藥研發(fā)力度。展望未來,人工智能技術也將為推動醫(yī)藥行業(yè)的創(chuàng)新發(fā)展發(fā)揮積極作用。憑借領先的原創(chuàng)AI技術,商湯科技此次公布的四大研究成果將為新藥研發(fā)的多個環(huán)節(jié)奠定創(chuàng)新基礎,助力醫(yī)藥行業(yè)智能化升級,進一步推動“醫(yī)療新基建”的長遠發(fā)展。目前,商湯也已經與國內外多家頂級藥企和基因檢測公司建立商業(yè)合作,共同利用AI技術加速新藥、基因等前沿創(chuàng)新方向的研發(fā),加快成果轉化,從而造福人類健康事業(yè)。