
“天下大勢,分久必合,合久必分。”
2025年的人工智能賽道,正呈現(xiàn)出一種強(qiáng)烈的分裂感。如果說前幾年是“百模大戰(zhàn)”的“戰(zhàn)國時代”,所有玩家都在同一條“Scaling Law”(規(guī)模法則)的跑道上野蠻沖鋒;那么2025年,市場則在劇烈的震蕩后,清晰地分化出了兩條截然相反、卻又彼此糾纏的敘事。
一個“向上”,一個“向下”。
“向上”的敘事由行業(yè)巨頭領(lǐng)銜。不久前,阿里通義Qwen3-Max在多個權(quán)威基準(zhǔn)測試中成功“登頂”,在被視為最能反映人類綜合偏好的LMArena盲測競技場上,躋身全球前三,一度超越了GPT-5-Chat的特定版本。這是國產(chǎn)大模型首次在性能的“珠峰”上,與OpenAI、Anthropic等全球頂級玩家實現(xiàn)了真正意義上的“同框競技”。這是“規(guī)模敘事”的延續(xù),是“大力出奇跡”的階段性勝利。
“向下”的敘事則由技術(shù)新貴驅(qū)動。幾乎在同一時間,DeepSeek發(fā)布了其最新的DeepSeek-V3.2-Exp模型,在性能與前代旗艦保持相當(dāng)?shù)那疤嵯拢珹PI價格悍然“腰斬”,降幅超過50%。尤其在輸出端,價格從12元/百萬Tokens驟降至3元/百萬Tokens。這場價格戰(zhàn)的背后并非是“流血補(bǔ)貼”,而是一場由底層技術(shù)突破發(fā)起的“成本突破”。
這不是偶然的巧合,而是兩條路線的必然碰撞。一方在不計代價地推高智能的“天花板”,另一方在不遺余力地?fù)舸┏杀镜摹暗匕濉薄?/strong>
這場關(guān)乎“極限性能”與“極致普惠”的博弈,正在重塑AI的商業(yè)邏輯。它所激發(fā)的矛盾,比模型參數(shù)本身更值得深思:當(dāng)“規(guī)模”遭遇“效率”,當(dāng)“開源”挑戰(zhàn)“閉源”,當(dāng)“中小企業(yè)的狂歡”遭遇“頭部巨頭的利潤保衛(wèi)戰(zhàn)”,這場戰(zhàn)爭的“中場”,究竟在走向何方?
“登頂”的執(zhí)念:AI巨頭的“3A游戲”
對于巨頭而言,似乎都對于一路陪伴走來的“Scaling Law”抱有執(zhí)念,不斷探索著規(guī)模與能力的邊界。
例如,Qwen3-Max的出現(xiàn),即是對“參數(shù)競賽”有效性的強(qiáng)力背書。在AI領(lǐng)域,“規(guī)模”一度是通往更高智能的唯一信仰。Qwen3-Max正是這一信仰的產(chǎn)物。
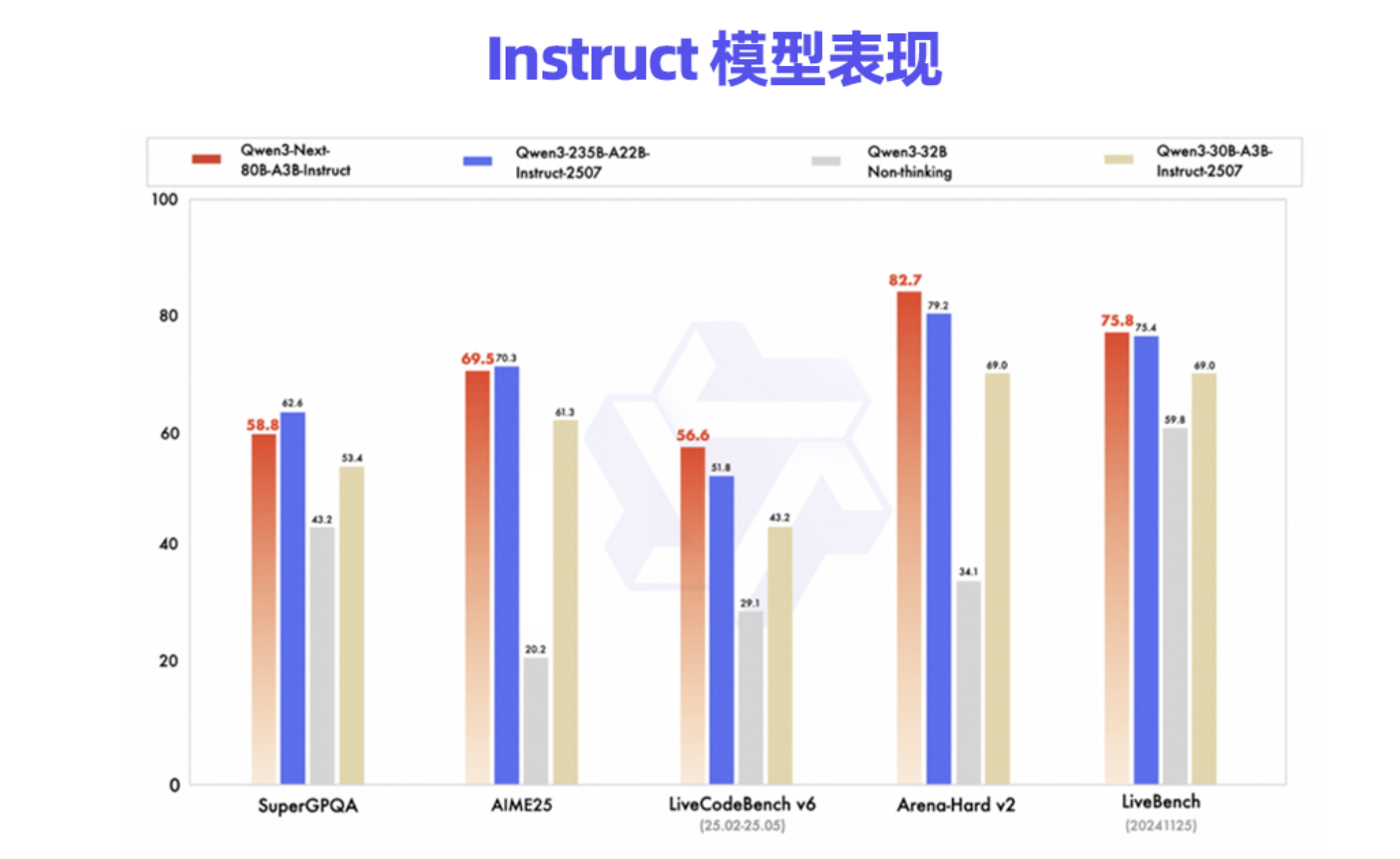

根據(jù)多方分析和披露,Qwen3-Max是一個參數(shù)量達(dá)到萬億級別的“龐然大物”,而巨大的體量也著實為其帶來了相匹配的實力:在SWE-Bench Verified上獲得了69.6分的世界級成績;在考驗Agent能力的Tau2-Bench上,超越了Claude Opus 4;在AIME等高難度推理任務(wù)上,其“Thinking”變體甚至取得了驚人的滿分或接近滿分的表現(xiàn)。
阿里不惜投入巨量資源,將Qwen3-Max推向SOTA,其戰(zhàn)略意圖清晰而堅定。這本質(zhì)上是一場只有巨頭才能玩得起的“3A游戲”。
正如在游戲行業(yè),3A大作意味著高昂的開發(fā)成本、頂級的制作水準(zhǔn)和龐大的宣發(fā)資源,大模型領(lǐng)域的“規(guī)模競賽”亦是如此。它是通過人力、財力、物力的極致堆砌,構(gòu)建起一道后來者難以逾越的性能壁壘和算力門檻。 目的很明確:在AGI的終極敘事中,必須手握一張能與OpenAI平起平坐的“王牌”,借以鞏固自身(尤其是云業(yè)務(wù))的優(yōu)勢,最后再依靠規(guī)模化應(yīng)用實現(xiàn)盈利。在企業(yè)客戶選擇云服務(wù)商時,一個“全球第三”的旗艦?zāi)P停湎笳饕饬x和信任背書價值千金。
然而,這場“登頂”的盛宴之下,潛藏著“參數(shù)陷阱”的冰冷現(xiàn)實。
第一個沖突在于“規(guī)模”與“成本”的邊際效益。萬億參數(shù)帶來了性能的提升,但也帶來了指數(shù)級增長的訓(xùn)練成本和推理成本。根據(jù)阿里云官網(wǎng)公布的價格,Qwen3-Max(0-32K檔)的輸入價格約為8.64元/百萬Tokens,輸出價格更是高達(dá)43.2元/百萬Tokens。這種定價,注定了它只能是少數(shù)頭部企業(yè)在核心、高價值場景中才能負(fù)擔(dān)的“奢侈品”。當(dāng)性能提升的邊際收益,開始難以覆蓋其高昂的推理成本時,“規(guī)模競賽”就觸碰到了商業(yè)落地的“玻璃天花板”。
第二個,則是開源策略與商業(yè)變現(xiàn)的矛盾。在國內(nèi)AI賽道中,“開源”正在成為行業(yè)的大勢所趨,然而矛盾在于,當(dāng)一個性能“足夠好”的開源模型可以免費、私有化部署時,有多少開發(fā)者還愿意為其閉源的、價格高昂的模型支付溢價?開源模型雖然“教育”了市場,卻也親手“稀釋”了其旗艦API的商業(yè)價值。
“破價”的利刃:創(chuàng)業(yè)公司“另辟蹊徑”的效率革命
一方面是巨頭的“3A游戲”,那么另一方面,以DeepSeek的“破價”則是資源相對薄弱的創(chuàng)業(yè)公司被迫選擇的“另辟蹊徑”。
財力雄厚的巨頭可以豪賭Scaling Law,但對于創(chuàng)業(yè)公司而言,除非擁有OpenAI那樣能撬動千億美元的戰(zhàn)略合作,否則在“參數(shù)陷阱”面前幾乎沒有試錯空間。 它們唯一的活路,就是通過極致的技術(shù)優(yōu)化——從架構(gòu)到算法再到工程——在有限的算力里“擠”出更多的能力,為自己,也為客戶“擠”出寶貴的利潤空間。
而對于DeepSeek而言,從其聲名鵲起,便是因為它的“破價”之所以在行業(yè)內(nèi)引發(fā)地震,因為它不是“補(bǔ)貼換市場”的互聯(lián)網(wǎng)舊劇本,而是由硬核技術(shù)驅(qū)動的“效率革命”。
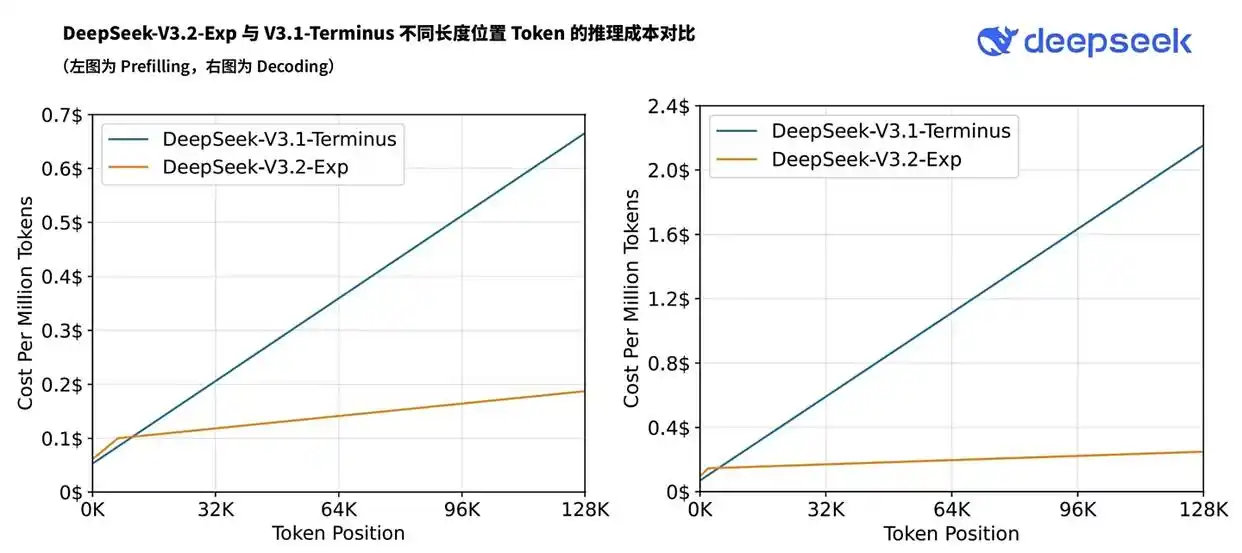
據(jù)了解,DeepSeek能夠有降價50%以上的底氣,來自于一個關(guān)鍵的技術(shù)突破:DSA(DeepSeek Sparse Attention)。
在傳統(tǒng)Transformer架構(gòu)中,注意力機(jī)制的計算復(fù)雜度是O(n^2)(n為序列長度),即每個Token都要和上下文中的所有其他Token進(jìn)行計算。在處理長文本時,這種“全局關(guān)注”會帶來災(zāi)難性的算力消耗。
DeepSeek V3.2-Exp(總參數(shù)量671B,激活參數(shù)37B的MoE模型)則徹底重寫了這一規(guī)則。DSA機(jī)制通過引入“Lightning Indexer”(閃電索引器)和“fine-grained selector”(細(xì)粒度選擇器),實現(xiàn)了兩階段的智能篩選。它不再“蠻力”地關(guān)注所有內(nèi)容,而是像一個高效的速讀者,先快速索引、評估上下文的重要性,然后只讓當(dāng)前Token與那些“真正相關(guān)”的Token進(jìn)行精細(xì)計算。
其結(jié)果是,在處理長文本任務(wù)時,DSA“極大減少了每層處理的Token數(shù)量”,從而“大幅削減了推理成本和處理時間”。最關(guān)鍵的一點是,根據(jù)DeepSeek的官方評測,V3.2-Exp的性能與V3.1-Terminus保持在同一水平。
這徹底改變了游戲的性質(zhì)。DeepSeek證明了,通過算法和架構(gòu)的極致創(chuàng)新,可以在不犧牲模型質(zhì)量的前提下,將推理成本壓縮一半甚至更多。
這是對“規(guī)模派”的一次精準(zhǔn)“降維打擊”。它向市場傳遞了一個清晰的信號:AI的競爭,已經(jīng)從單純比拼“肌肉”(參數(shù)規(guī)模)的1.0時代,進(jìn)入了比拼“神經(jīng)效率”(算法與工程優(yōu)化)的2.0時代。
夾縫中的“新大陸”:API價格戰(zhàn)與巨頭的“利潤保衛(wèi)戰(zhàn)”
高階模型所形成的巨大價格鴻溝,正是當(dāng)前AI產(chǎn)業(yè)核心矛盾的爆發(fā)點。在這道鴻溝的兩側(cè),是中小企業(yè)和巨頭們截然不同的命運(yùn)。
對于數(shù)以萬計的中小企業(yè)、初創(chuàng)公司和獨立開發(fā)者而言,以DeepSeek為代表的“技術(shù)破價”無異于開辟了一片“新大陸”。在此之前,AI應(yīng)用的成本是一只“攔路虎”,如今結(jié)束技術(shù)手段,正將AI的成本屬性從“咨詢費”拉向“水電費”。當(dāng)API成本降低50%甚至90%時,AI應(yīng)用的“可行性”就可以完成“從0到1”。
正如行業(yè)分析師所指出的,DeepSeek的低成本創(chuàng)新,正在推動AI應(yīng)用“從頭部企業(yè)壟斷轉(zhuǎn)向長尾場景滲透”。這符合“杰文斯悖論”(Jevons Paradox)的經(jīng)典邏輯:技術(shù)效率的提升(成本降低)并不會減少總消耗,反而會因為門檻的降低而激發(fā)海量的、前所未有的新需求,最終帶來算力總需求的爆發(fā)式增長。
然而,中小企業(yè)的狂歡,映襯出的卻是頭部巨頭的焦慮。DeepSeek的“技術(shù)破價”更是將這場沖突推向了高潮。
事實上,一場殘酷的“API價格戰(zhàn)”早已在國內(nèi)AI巨頭(如阿里、百度、騰訊、字節(jié))之間打響。早在2024年,字節(jié)豆包的“白菜價”就已迫使阿里云(Qwen-Long降價97%)和百度(文心兩大主力模型免費)倉促應(yīng)戰(zhàn)。巨頭們不惜大幅降低API單價,甚至將中小型模型免費,其核心目的就是“搶占AI云市場”的入口。 他們試圖用“模型補(bǔ)貼”換取“云客戶”,將用戶鎖定在自己的生態(tài)高墻內(nèi)。
這場“價格戰(zhàn)”與“效率戰(zhàn)”的疊加,讓巨頭們陷入了經(jīng)典的兩難困境。
一位不愿透露姓名的大模型頭部企業(yè)從業(yè)者在一次模擬采訪中這樣表述:“我們內(nèi)部現(xiàn)在很分裂。一方面,你必須跟進(jìn)(降價),市場份額丟了就再也回不來了,云業(yè)務(wù)的增長指望著這個。另一方面,旗艦?zāi)P停ㄈ鏠wen3-Max)的推理成本是實打?qū)嵉模祪r就是‘割肉’。”
“我們現(xiàn)在的策略是分裂的:用免費的中小模型去‘跑量’,穩(wěn)住開發(fā)者生態(tài);同時用頂尖的旗艦?zāi)P腿ァ?biāo)桿’,服務(wù)那些真正愿意為0.1分性能提升付費的頭部客戶。”但在靠效率的創(chuàng)業(yè)公司的“攪局”之下,巨頭用‘規(guī)模’砸出來的性能溢價,正在被他們迅速拉平。
這段基于行業(yè)普遍現(xiàn)狀的模擬表述,精準(zhǔn)地道出了巨頭的“利潤保衛(wèi)戰(zhàn)”有多么艱難。他們試圖用“云服務(wù)+模型”的生態(tài)綁定構(gòu)建“護(hù)城河”,但在絕對的性價比面前,這種綁定的吸引力正在受到嚴(yán)峻考驗。
超越“規(guī)模”與“效率”,AI價值正被再定義
Qwen3-Max的“登頂”和DeepSeek V3.2-Exp的“破價”,看似是兩條背道而馳的路線,但它們聯(lián)手導(dǎo)演的這場“極限沖突”,實際上共同終結(jié)了大模型競爭的“蠻荒時代”,并提前揭示了“中場戰(zhàn)事”的終局走向。

首先,未來“規(guī)模派”和“效率派”必然走向融合。
“規(guī)模派”同樣意識到單純堆料的不可持續(xù)。Qwen3-Max本身采用先進(jìn)的MoE(混合專家)架構(gòu),就是其主動吸收“效率”技術(shù)的明證。未來,巨頭們必須將DSA這類稀疏算法和極致的推理優(yōu)化,作為其旗艦?zāi)P偷摹皹?biāo)配”,否則其“規(guī)模”將因成本過高而喪失意義。
而“效率派”也不會永遠(yuǎn)停留在“性價比”的舒適區(qū)。它們必須利用“技術(shù)破價”換來的海量市場和數(shù)據(jù)飛輪,反哺更高性能、更大規(guī)模模型的研發(fā)。否則,它們也將在“效率”的單一維度上,陷入新一輪的“內(nèi)卷”。
其次,這場沖突正在倒逼AI產(chǎn)業(yè)回歸商業(yè)本質(zhì):從“模型跑分”轉(zhuǎn)向“應(yīng)用價值”。
當(dāng)最頂尖的模型和性價比最高的模型同時擺在貨架上,客戶的選擇不再是盲目的“追高”,而是精準(zhǔn)的“適配”。市場被清晰地劃分:少數(shù)高敏、高價值的場景去追逐頂尖模型的極限性能;而海量的、對成本敏感的“長尾應(yīng)用”,則會擁抱效率模型的極致效率。
這場由“規(guī)模”和“效率”共同導(dǎo)演的戲劇性沖突,其真正的價值在于“擠出”了AI的泡沫。它迫使所有玩家——無論是手握萬億參數(shù)的巨頭,還是掌握效率利器的新貴——都必須回答同一個終極問題:
你所提供的智能,究竟為客戶創(chuàng)造了多少可衡量的價值?
在AI的中場戰(zhàn)事中,誰能率先回答好這個問題,誰才能定義下半場。