3 月 18 日,昆侖萬維正式開源首款工業界多模態思維鏈推理模型 Skywork-R1V,開啟多模態思考新時代。繼 Skywork-R1V 首次成功實現“強文本推理能力向視覺模態的遷移”之后,昆侖萬維再度發力,今天正式開源多模態推理模型的全新升級版本 —— Skywork-R1V 2.0(以下簡稱 R1V 2.0) 。
01
R1V 2.0 性能全面提升并開源,視覺與文本推理能力雙管齊下
Skywork-R1V 2.0 是當前最均衡兼顧視覺與文本推理能力的開源多模態模型,該多模態模型在高考理科難題的深度推理與通用任務場景中均表現優異,真正實現多模態大模型的“深度 + 廣度”統一。升級后的 R1V 2.0 模型頗具亮點:
-中文場景領跑:理科學科題目(數學/物理/化學)推理效果拔群,打造免費AI解題助手;
-開源巔峰:38B 權重 + 技術報告全面開源,推動多模態生態建設;
-技術創新標桿:多模態獎勵模型(SkyworkVL Reward) 與 混合偏好優化機制(MPO),全面提升模型泛化能力;選擇性樣本緩沖區機制(SSB),突破強化學習“優勢消失”瓶頸。
在多個權威基準測試中,R1V 2.0 相較于 R1V 1.0 在文本與視覺推理任務中均實現顯著躍升。無論是專業領域任務,如數學推理、編程競賽、科學分析,還是通用任務,如創意寫作與開放式問答,R1V 2.0 都呈現出極具競爭力的表現:
-在 MMMU 上取得 73.6 分,刷新開源 SOTA 紀錄;
-在 Olympiad Bench 上達到 62.6 分,顯著領先其他開源模型;
-在 MathVision、MMMU-PRO 與 MathVista 等多項視覺推理榜單中均表現優異,多項能力已可媲美閉源商業模型,堪稱當前開源多模態推理模型中的佼佼者。
在與開源多模態模型的對比中,R1V 2.0 的視覺推理能力(在眾多開源模型里)脫穎而出。
如下圖所示,R1V2.0 也展現出媲美商業閉源多模態模型的實力。
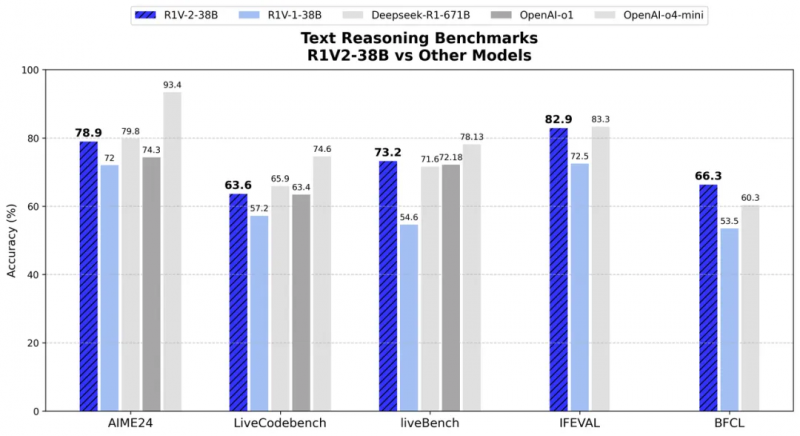
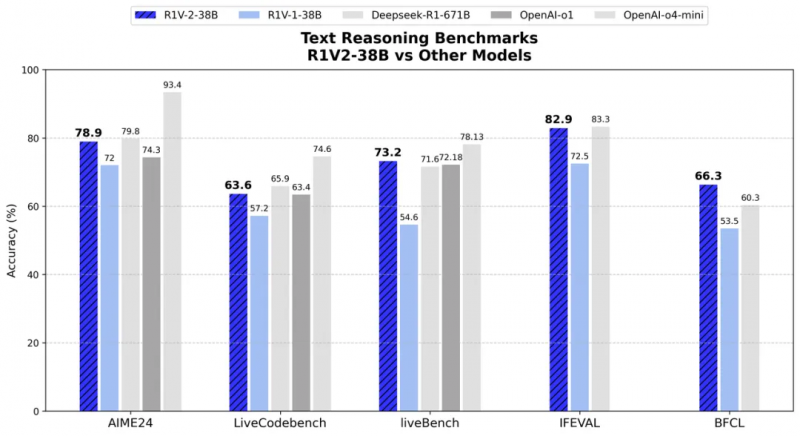
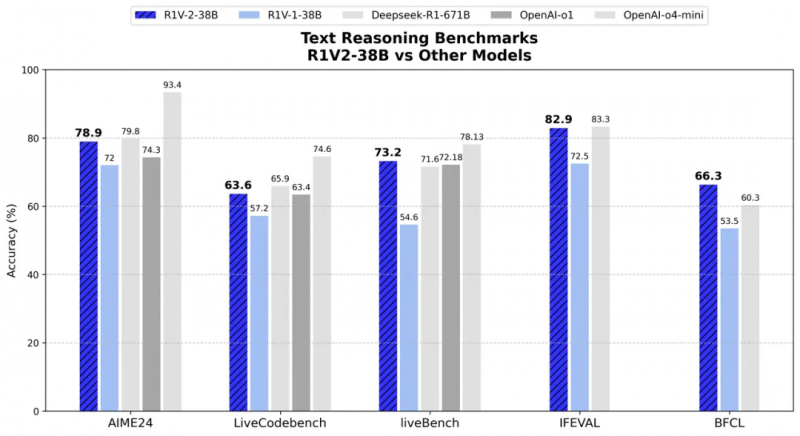
而在文本推理方面,在 AIME2024 和 LiveCodeBench 等挑戰中,R1V 2.0 分別取得了78.9 分和 63.6 分,展現出了人類專家級數學與代碼理解能力。在與專用文本推理模型對比中,R1V2.0 同樣展現出卓越的文本推理能力。
02
技術亮點一:推出多模態獎勵模型 Skywork-VL Reward,全面開源
自 R1V 1.0 開源以來,昆侖萬維團隊收獲了來自全球開發者與研究者的廣泛反饋。在模型推理能力顯著提升的同時,團隊也發現,過度集中于推理任務的訓練,會限制模型在其他常規任務場景下的表現,影響整體的泛化能力與通用表現。
為實現多模態大模型在“深度推理”與“通用能力”之間的最佳平衡,R1V 2.0 引入了全新的「多模態獎勵模型 Skywork-VL Reward」及「規則驅動的混合強化訓練機制」。在顯著增強推理能力的同時,進一步穩固了模型在多任務、多模態場景中的穩定表現與泛化能力。
Skywork-VL Reward,開啟多模態強化獎勵模型新篇章:
當前,行業中多模態獎勵模型的缺乏,已成為強化學習在 VLM(Vision-Language Models)領域進一步發展的關鍵瓶頸。
現有獎勵模型難以準確評價跨模態推理所需的復雜理解與生成過程。為此,昆侖萬維推出了 SkyworkVL Reward模型,既可為通用視覺語言模型(VLM)提供高質量獎勵信號,又能精準評估多模態推理模型長序列輸出的整體質量,同時也可以作為并行線上推理最優答案選擇的利器。
這種能力使得 Skywork-VL Reward 模型在多模態強化學習任務中具有廣泛的適用性,促進了多模態模型的協同發展:
-跨模態引領者:率先提出多模態推理與通用獎勵模型,推動多模態強化學習;
-榜單標桿:在視覺獎勵模型評測中名列第一,7B 權重與技術報告全面開源;
-信號全覆蓋:支持從短文本到長序列推理的多元化獎勵判別。
Skywork-VL Reward 在多個權威評測榜單中表現優異:在視覺獎勵模型評測榜單 VL-RewardBench 中取得了 73.1 的SOTA成績,同時在純文本獎勵模型評測榜單 RewardBench 中也斬獲了高達 90.1 的優異分數,全面展示了其在多模態和文本任務中的強大泛化能力。
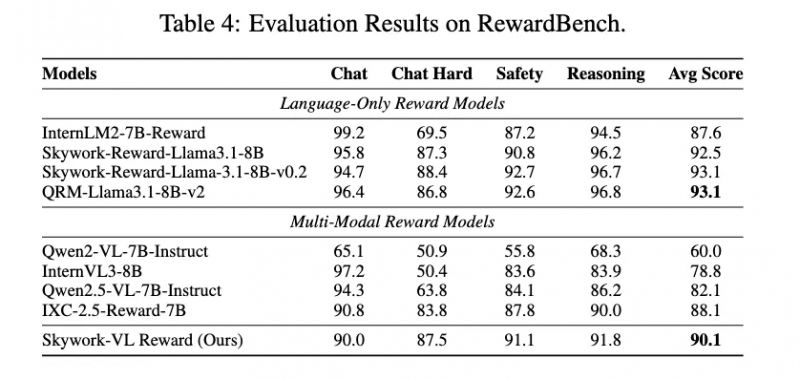
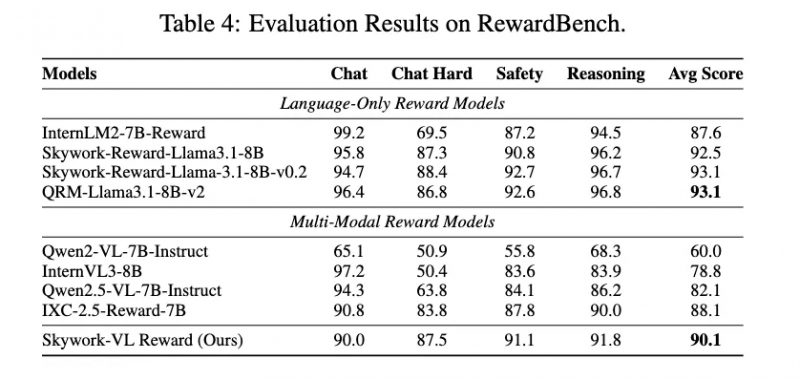
為回饋社區和行業,團隊也將 Skywork-VL Reward 完整開源。
03
技術亮點二:引入多重優化策略提升核心效果
長期以來,大模型訓練面臨“深度推理提升”與“通用能力保持”的難以兼得難題。為解決這一“推理–通用”的能力蹺蹺板問題,以及解決通用問題沒有直接可驗證的答案的挑戰,R1V 2.0 引入了 MPO(Mixed Preference Optimization,混合偏好優化) 機制,并在偏好訓練中充分發揮 Skywork-VL Reward 獎勵模型的指導作用。
和 R1V 1.0 思路類似,我們使用提前訓練好的 MLP 適配器,直接將視覺編碼器 internVIT-6B 與原始的強推理語言模型 QwQ-32B 連接,形成 R1V 2.0-38B 的初始權重。這樣一來,R1V 2.0 在啟動即具備一定的多模態推理能力。
在通用任務訓練階段,R1V 2.0 借助 Skywork-VL Reward 提供的偏好信號,引導模型進行偏好一致性優化,從而確保模型在多任務、多領域下具備良好的通用適應能力。實驗證明,Skywork-VL Reward 有效實現了推理能力與通用能力的協同提升,成功實現“魚與熊掌兼得”。
在訓練深度推理能力時,R1V 2.0 在訓練中采用了 基于規則的群體相對策略優化GRPO(Group Relative Policy Optimization) 方法。該策略通過同組候選響應之間的相對獎勵比較,引導模型學會更精準的選擇和推理路徑。
R1V 2.0 所采用的多模態強化訓練方案,標志著大模型訓練范式的又一次重要革新,也再次驗證了強化學習在人工智能領域無法撼動的地位。通過引入通用性更強的獎勵模型 Skywork-VL Reward,以及高效穩定的樣本利用機制 SSB,我們不僅進一步提升了R1V系列模型在復雜任務中的推理能力,同時也將開源模型跨模態推理泛化能力提升到了全新高度。
R1V 2.0 的誕生,不僅推動了開源多模態大模型在能力邊界上的突破,更為多模態智能體的搭建提供了新的基座模型。
04
面向AGI的持續開源
最近一年以來,昆侖萬維已陸續開源多款核心模型:
開源系列:
1. Skywork-R1V 系列:38B 視覺思維鏈推理模型,開啟多模態思考時代;
2. Skywork-OR1(Open Reasoner 1)系列:中文邏輯推理大模型,7B和32B最強數學代碼推理模型;
3. SkyReels系列:面向AI短劇創作的視頻生成模型;
4. Skywork-Reward:性能卓越的全新獎勵模型。
這些項目在 Hugging Face 上廣受歡迎,引發了開發者社區的廣泛關注與深入討論。
我們堅信,開源驅動創新,AGI 終將到來。
正如 DeepSeek 等優秀團隊所展現的那樣,開源模型正逐步彌合與閉源系統的技術差距,乃至實現超越。R1V 2.0 不僅是當前最好的開源多模態推理模型,也是我們邁向 AGI 路上的又一重要里程碑。昆侖萬維將繼續秉持“開源、開放、共創”的理念,持續推出領先的大模型與數據集,賦能開發者、推動行業協同創新,加速通用人工智能(AGI)的實現進程。