隨著大模型技術迎來顛覆性突破,新興AI應用大量涌現,不斷重塑著人類、機器與智能的關系。
為此,昆侖萬維集團重磅推出《天工一刻》系列產業觀察欄目。在本欄目中,我們將對大模型產業熱點、技術創新、應用案例進行深度解讀,同時邀請學術專家、行業領袖分享優秀的大模型行業趨勢、技術進展,以饗讀者。
MoE混合專家大模型最近究竟有多火?
舉個例子,在此前的GTC 2024上,英偉達PPT上的一行小字,吸引了整個硅谷的目光。
“GPT-MoE 1.8T”
這行小字一出來,X(推特)上直接炸鍋了。
“GPT-4采用了MoE架構”,這條整個AI圈瘋傳已久的傳言,竟然被英偉達給“無意中”坐實了。消息一出,大量AI開發者們在社交平臺上發帖討論,有的看戲吐槽、有的認真分析、有的開展技術對比,一時好不熱鬧。
MoE大模型的火熱,可見一斑。
近半年多以來,各類MoE大模型更是層出不窮。在海外,OpenAI推出GPT-4、谷歌推出Gemini、Mistral AI推出Mistral、連馬斯克xAI的最新大模型Grok-1用的也是MoE架構。
而在國內,昆侖萬維也于今年4月17日正式推出了新版MoE大語言模型「天工3.0」,擁有4000億參數,超越了3140億參數的Grok-1,成為全球最大的開源MoE大模型。
MoE究竟是什么?它有哪些技術原理?它的優勢和缺點是什么?它又憑什么能成為當前最火的大模型技術?
以上問題,本文將逐一回答。
MoE核心邏輯:術業有專攻
MoE,全稱Mixture of Experts,混合專家模型。
MoE是大模型架構的一種,其核心工作設計思路是“術業有專攻”,即將任務分門別類,然后分給多個“專家”進行解決。
與MoE相對應的概念是稠密(Dense)模型,可以理解為它是一個“通才”模型。
一個通才能夠處理多個不同的任務,但一群專家能夠更高效、更專業地解決多個問題。
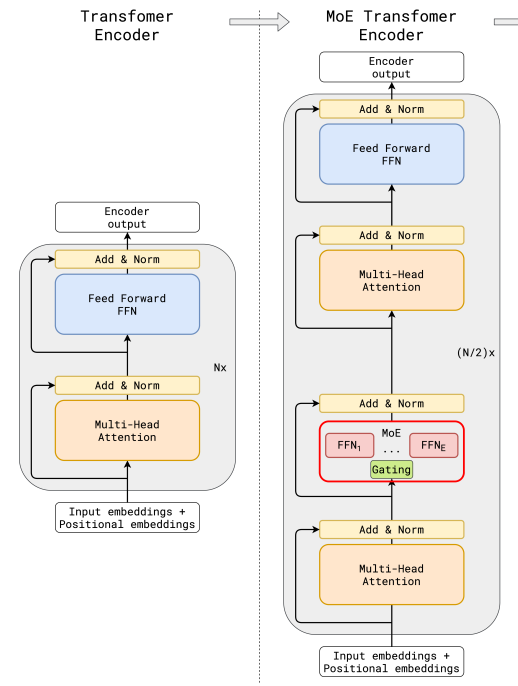
(圖片來源:《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding》)
上圖中,左側圖為傳統大模型架構,右圖為MoE大模型架構。
兩圖對比可以看到,與傳統大模型架構相比,MoE架構在數據流轉過程中集成了一個專家網絡層(紅框部分)。
下圖為紅框內容的放大展示:
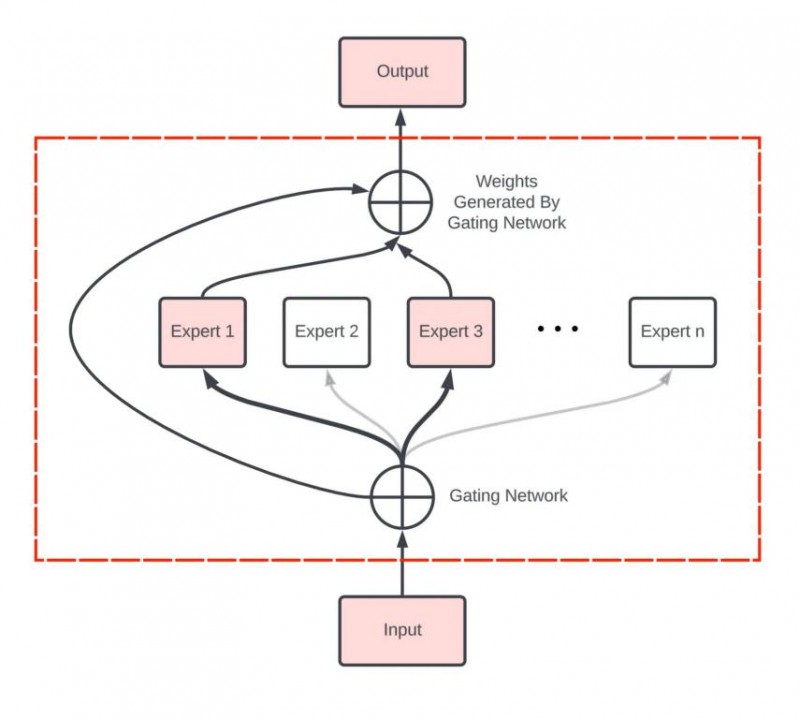
(圖片來源:Zian (Andy) Wang)
專家網絡層的核心由門控網絡(Gating Network)和一組專家模型(Experts)構成,其工作流程大致如下:
1、數據首先會被分割多個區塊(Token),每組數據進入專家網絡層時,首先會進入門控網絡。
2、門控網絡將每組數據分配給一個或多個專家,每個專家模型可以專注于處理該部分數據,“讓專業的人做專業的事”。
3、最終,所有專家的輸出結果匯總,系統進行加權融合,得到最終輸出。
當然,以上只是一個概括性描述,關于門控網絡的位置、模型、專家數量、以及MoE與Transformer架構的具體結合方案,各家方案都略有差別,但核心思路是一致的。
與一個“通才網絡”相比,一組術業有專攻的“專家網絡”能夠提供更好的模型性能、更好地完成復雜的多種任務,同時,也能夠在不顯著增加計算成本的情況下大幅增加模型容量,讓萬億參數級別的大模型成為可能。
Scaling Law:讓模型更大
MoE之所以受到整個AI大模型行業的追捧,一個核心的原因是——今天的大模型,正迫切地需要變得更大。
而這一切的原因,則要追溯到Scaling Law。
Scaling Law,規模定律,也譯為縮放定律。這不是一個嚴格的數學定律,它只是用來描述物理、生物、計算機等學科中關于系統復雜屬性變化的規律。
而在大語言模型里,從Scaling Law能夠衍生出一個通俗易懂的結論:
“模型越大,性能越好。”
更準確的描述是:當AI研究人員不斷增加大語言模型的參數規模時,模型的性能將得到顯著提升,不僅能獲得強大的泛化能力,甚至出現智能涌現。
自人工智能誕生以來,人們一直試圖設計出更巧妙的算法、更精密的架構,希望通過人類的智慧將機器設計得更聰明,達到通用人工智能。
但以OpenAI為代表的業內另一種聲音說:“我反對!”
2019年,機器學習先驅Rich Sutton曾經發表過一篇經典文章《The Bitter Lesson》,該文幾乎被全體OpenAI成員奉為圭臬。
文中認為,也許這種傳統方法是一種錯誤的思路;也許試圖用人類智慧設計出通用人工智能的這個路徑,在過去幾十年間,讓整個行業都走了大量彎路,付出了苦澀的代價。
而真正正確的路徑是:不斷擴大模型規模,再砸進去天文數字的強大算力,讓Scaling Law創造出更“聰明”的人工智能,而不是靠人類自己去設計。
在這一輪大模型火起來之前,遵循這一思路的科學家一直是業內的少數派,但自從GPT路線在自然語言處理上大獲成功之后,越來越多研究人員加入這一陣列。
追求更大的模型,成為了人工智能性能突破的一大核心思路。
然而問題隨之而來。
眾所周知,隨著大模型越來越大,模型訓練的困難程度、資源投入、訓練時間都在指數型提升,可模型效果卻無法保證等比例提升。
隨著模型越來越大,穩定性也越來越差,種種綜合原因讓大模型參數量長久以來限制在百億與千億級別,難以進一步擴大。
如何在有限的計算資源預算下,如何訓練一個規模更大、效果更好的大模型,成為了困擾行業的問題。
此時,人們將目光投向了MoE。
MoE:突破萬億參數大關
早在1991年,兩位人工智能界的泰斗Michael Jordan與Geoffrey Hinton就聯手發布了MoE領域的奠基論文《Adaptive Mixtures of Local Experts》,正式開創了這一技術路徑。
2020年,《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding》論文又首次將MoE技術引入到Transformer架構中,拉開了“MoE+大模型”的大幕。
2022年,Google《Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity》論文中提出的MoE大模型更是一舉突破了萬億參數大關。
Switch Transformers模型參數達到1.57萬億,與此前的T5模型相比,在相同的計算資源下獲得高達7倍的模型預訓練速度提升,并實現了4倍的模型加速。
而正如文章開頭所言,本屆GTC上英偉達側面證實了那個公認的傳言:OpenAI在2023年推出的GPT-4,同樣采用了MoE架構,其模型效果與計算效率都得到了顯著提升。
總結起來,MoE在大模型領域的優勢包括:
1、與傳統的Dense模型相比,MoE能夠在遠少于前者所需的計算資源下進行有效的預訓練,計算效率更高、速度更快,進而使得模型規模得到顯著擴大,獲得更好的AI性能。
2、由于MoE在模型推理過程中能夠根據輸入數據的不同,動態地選擇不同的專家網絡進行計算,這種稀疏激活的特性能夠讓模型擁有更高的推理計算效率,從而讓用戶獲得更快的AI響應速度。
3、由于MoE架構中集成了多個專家模型,每個專家模型都能針對不同的數據分布和構建模式進行搭建,從而顯著提升大模型在各個細分領域的專業能力,使得MoE在處理復雜任務時性能顯著變好。
4、針對不同的專家模型,AI研究人員能夠針對特定任務或領域的優化策略,并通過增加專家模型數量、調整專家模型的權重配比等方式,構建更為靈活、多樣、可擴展的大模型。
不過,天下沒有免費的性能提升,在擁有種種優勢之于,MoE架構也存在著不少挑戰。
由于MoE需要把所有專家模型都加載在內存中,這一架構對于顯存的壓力將是巨大的,通常涉及復雜的算法和高昂的通信成本,并且在資源受限設備上部署受到很大限制。
此外,隨著模型規模的擴大,MoE同樣面臨著訓練不穩定性和過擬合的問題、以及如何確保模型的泛化性和魯棒性問題、如何平衡模型性能和資源消耗等種種問題,等待著大模型開發者們不斷優化提升。
結語
總結來說,MoE架構的核心思想是將一個復雜的問題分解成多個更小、更易于管理的子問題,并由不同的專家網絡分別處理。這些專家網絡專注于解決特定類型的問題,通過組合各自的輸出來提供最終的解決方案,提高模型的整體性能和效率。
當前,MoE仍舊是一個新興的大模型研究方向,研究資料少、資源投入大、技術門檻高,其研發之初仍舊以海外巨頭為主導,國內只有昆侖萬維等少數玩家能夠推出自研MoE大模型。
不過,值得注意的是,雖然以擴大模型參數為核心的“暴力出奇跡”路線主導了當前的人工智能行業研究,但時至今日也沒有人能拍著胸脯保證,Scaling Law就是人類通往通用人工智能的唯一正確答案。
從1991年正式提出至今,MoE架構已歷經了30年歲月;深度神經網絡更是70年前就已提出的概念,直到近十多年間才取得突破,帶領人類攀上人工智能的又一座高峰。
MoE不是人工智能技術前進道路的終點,它甚至不會是大模型技術的最終答案。未來,還將有大量感知、認知、計算、智能領域的挑戰擺在研究者面前,等待著人們去逐一解決。
所幸的是,怕什么真理無窮,進一寸有一寸的歡喜。
參考資料:
1、GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
2、Mixture of Experts: How an Ensemble of AI Models Decide As One
3、Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
4、「天工2.0」MoE大模型發布