
4月18日晚間,Meta正式發(fā)布全新一代開源模型Llama3。本次發(fā)布的Llama3涵蓋了兩個版本,即Llama3-8B和Llama3-70B,它以其8B的模型規(guī)模,超越了去年70B模型的性能。Meta宣稱Llama 3-8B和Llama 3-70B是目前同體量下,性能最好的開源模型。
在開源與閉源路線的長期“較量”中,Llama 3的問世,無疑為開源社區(qū)注入了一劑強(qiáng)心針,不僅是對開源模式潛力的有力證明,更激勵更多的企業(yè)和開發(fā)者加入到這一開放、協(xié)作的生態(tài)系統(tǒng)中。
針對Llama 3的具體能力表現(xiàn),前不久,國內(nèi)人工智能權(quán)威機(jī)構(gòu)清華大學(xué)基礎(chǔ)模型研究中心正式發(fā)布《SuperBench大模型綜合能力評測報告》,測試了國內(nèi)外數(shù)款大模型在語義、代碼、對齊、智能體和安全五個評測集中的表現(xiàn)。

根據(jù)報告的評分結(jié)果,Llama3-70B模型的表現(xiàn)出色,其得分在眾多國內(nèi)外頂尖模型中位列第六位。
大模型之家還注意到,在SuperBench的評測榜單中,第一梯隊的大模型已經(jīng)不再是海外大模型“霸榜”的局面,有兩款來自國內(nèi)企業(yè)的大模型產(chǎn)品在語義理解能力表現(xiàn)中超越了Llama-3,其中一款是智譜AI開發(fā)的GLM-4,另一款是百度推出的文心一言4.0。可見,歷經(jīng)一年的技術(shù)發(fā)展與沉淀,全球大模型技術(shù)能力的競爭格局正在悄然發(fā)生改變,中國最前沿的大型人工智能模型已經(jīng)達(dá)到了國際領(lǐng)先水平,成為全球人工智能領(lǐng)域的引領(lǐng)者。
多項評分領(lǐng)先,國產(chǎn)大模型對癥下藥飛根據(jù)SuperBench發(fā)布的評測報告,GLM-4在各項子項評測中均展現(xiàn)出優(yōu)秀的成績。特別是在知識-常識能力方面,GLM-4以77.3分的優(yōu)異成績榮登全球第二、國內(nèi)第一的寶座。同時其強(qiáng)大的多模態(tài)處理能力使GLM-4不僅能處理文本信息,更能理解和生成圖片、文件及視頻內(nèi)容,從而在圖文理解和生成任務(wù)中脫穎而出,精準(zhǔn)回應(yīng)用戶的復(fù)雜需求。
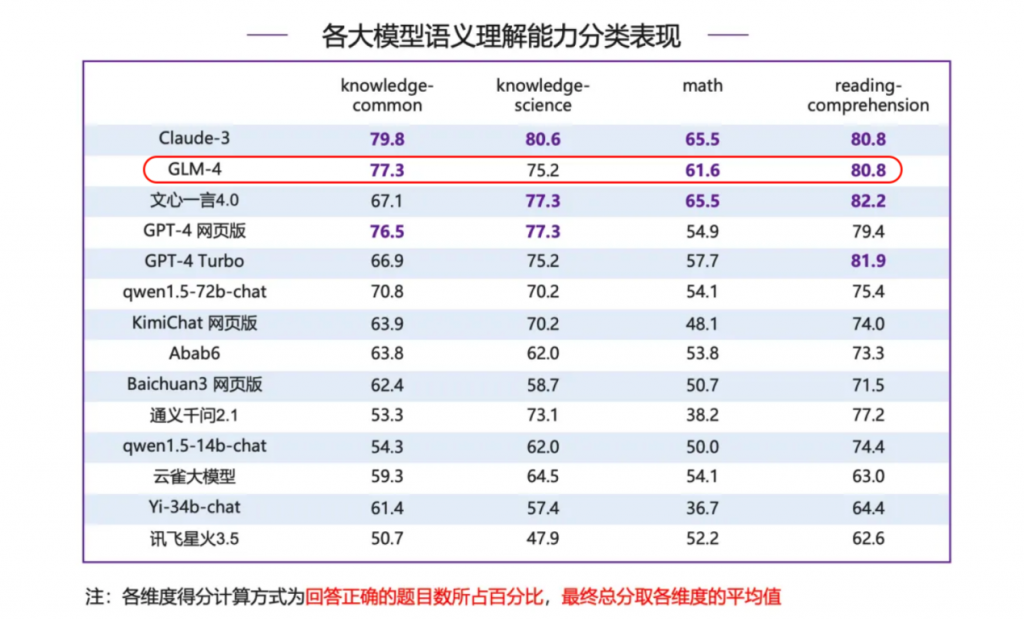
在長文本處理能力上,GLM-4具備128k的上下文處理能力,能夠輕松應(yīng)對長達(dá)300頁的文本。在MMLU、GSM8K、BBH、HellaSwag等多個數(shù)據(jù)集上,GLM-4的表現(xiàn)均達(dá)到了GPT-4相應(yīng)性能的94%至100%,展現(xiàn)出卓越的性能。
通過有機(jī)整合來自不同模態(tài)的上下文信息,GLM-4增強(qiáng)了對整個交互情境的理解能力,這種整合能力使得模型在應(yīng)對需要綜合多種信息源的復(fù)雜任務(wù)時,能夠提供更加精準(zhǔn)和全面的回答,進(jìn)一步提升用戶體驗。
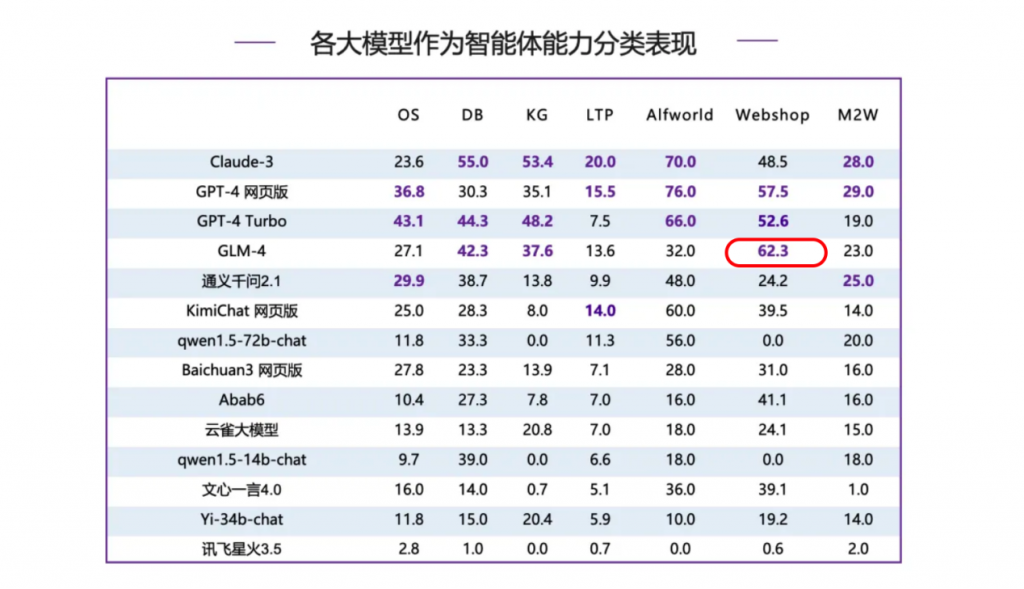
此外,在智能體能力方面,GLM-4同樣表現(xiàn)出色,為產(chǎn)業(yè)化創(chuàng)造了條件。例如在電商場景中,依托出色的自然語言處理(NLP)能力,能夠理解和解釋用戶的查詢、評論以及商品描述,從而準(zhǔn)確捕捉用戶的購物意圖和偏好。
通過先進(jìn)的推薦系統(tǒng)技術(shù),包括基于協(xié)同過濾、深度學(xué)習(xí)模型等,模型能夠根據(jù)用戶的個性化需求和行為數(shù)據(jù),以及通過利用大規(guī)模數(shù)據(jù)處理和分析技術(shù),實現(xiàn)對用戶提供更具針對性和前瞻性的服務(wù)。
大模型之家還了解到,智譜AI推出了GLMs個性化智能體定制功能,允許用戶無需具備編程基礎(chǔ),通過簡單的語言提示輕松創(chuàng)建屬于自己的GLM智能體,大幅降低大模型的使用門檻。

此外,GLM-4模型在圖像生成和理解方面也實現(xiàn)了重大突破。通過集成CogView3代模型,GLM-4不僅能夠生成具有藝術(shù)感的高質(zhì)量圖像,還能對圖像內(nèi)容進(jìn)行深入分析和理解。這種能力極大地豐富了模型在處理涉及視覺信息的任務(wù)時的表現(xiàn),使得GLM-4能夠更準(zhǔn)確地捕捉和回應(yīng)圖像中的細(xì)節(jié)和上下文。
學(xué)術(shù)+商業(yè)雙管齊下,國產(chǎn)AI走向成熟
中國大模型技術(shù)的快速發(fā)展,也讓越來越多的國產(chǎn)大模型登上了世界權(quán)威評測的榜單。不僅是SuperBench評測,在OpenCompass2.0公布的2023年度大模型公開評測榜單中,也能夠看到智譜GLM-4、阿里巴巴Qwen-Max、百度文心一言4.0位列榜單前列,中美在人工智能領(lǐng)域的技術(shù)差距正在以超乎想象的速度拉近。
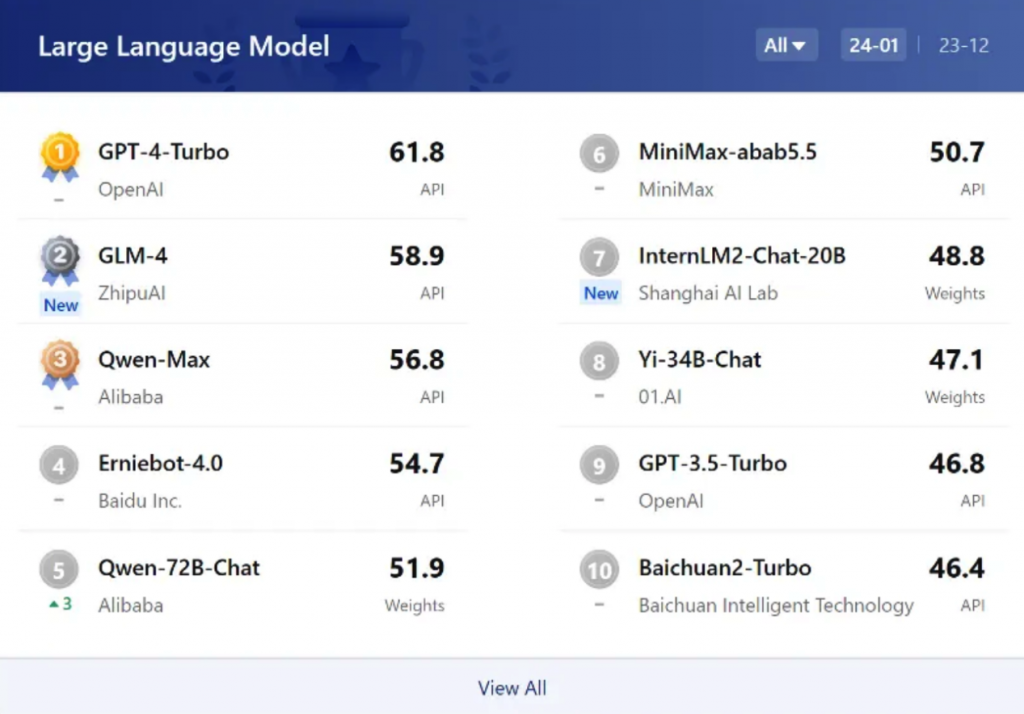
大模型的技術(shù)革命,不僅為人工智能賦予了“涌現(xiàn)”的能力,也為行業(yè)逐漸“涌現(xiàn)”出了各種機(jī)會,我國人工智能企業(yè)也在積累中迎來爆發(fā),全球AI發(fā)展的態(tài)勢也逐漸將人工智能擺在了關(guān)鍵競爭高地。智譜AI CEO張鵬曾多次表示,智譜要將“實現(xiàn)大模型生成AI的全鏈路自主可控”作為企業(yè)的核心競爭力。
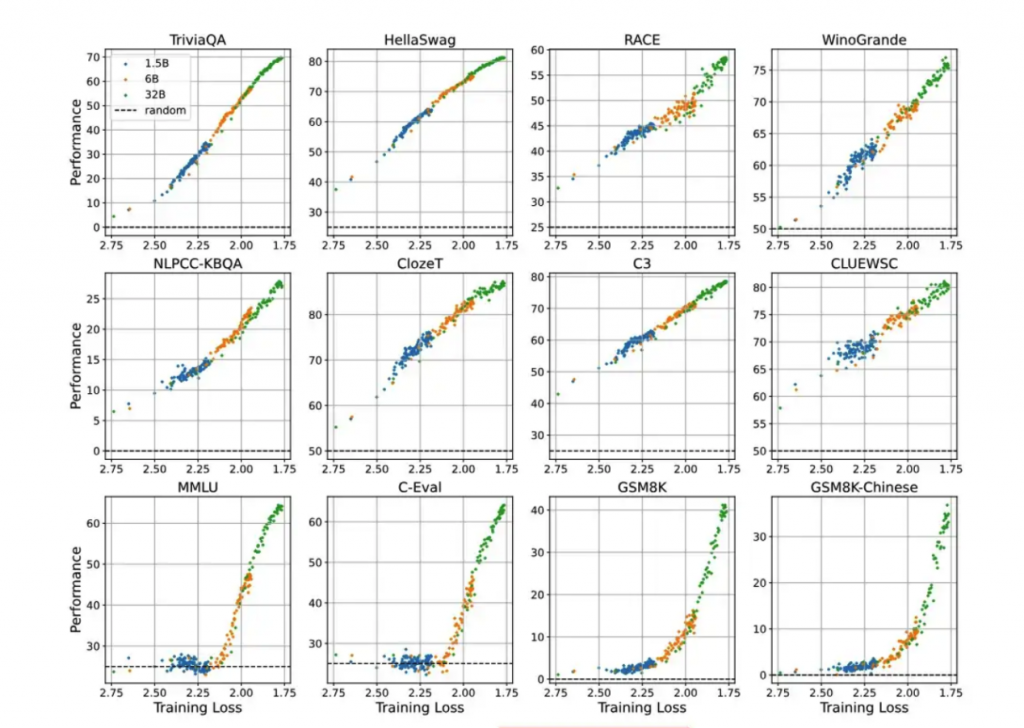
在學(xué)術(shù)領(lǐng)域,中國大模型從業(yè)者在多項研究領(lǐng)域都走在行業(yè)前沿。例如在近期研究中,智譜團(tuán)隊證明了依靠更好的預(yù)訓(xùn)練質(zhì)量,在更小模型上也能實現(xiàn)了更優(yōu)的模型能力,顛覆了大模型行業(yè)“大力出奇跡”的思維定勢。
此外,智譜AI帶來了提升大模型與人類偏好一致性的強(qiáng)化學(xué)習(xí)系統(tǒng)——ChatGLM-RLHF框架,該框架由三個主要部分組成:數(shù)據(jù)收集與處理、獎勵模型訓(xùn)練和策略模型訓(xùn)練。
首先,ChatGLM-RLHF通過從SFT模型生成的兩個輸出中選擇一個更優(yōu)的響應(yīng),完成數(shù)據(jù)的收集。再利用收集到的偏好數(shù)據(jù)來訓(xùn)練一個獎勵模型,預(yù)測最符合用戶偏好的回答。最后,使用獎勵模型來指導(dǎo)模型的優(yōu)化過程,通過最大化累積獎勵來提升模型的表現(xiàn)。
在三個步驟的協(xié)同工作下,大模型能夠更加“通人性”,更清晰地理解人類的喜好與需求,才能夠更好地為用戶提供服務(wù)
在眾多權(quán)威評測中的亮眼表現(xiàn)以及在研發(fā)領(lǐng)域的累累碩果,見證著中國大模型企業(yè)的創(chuàng)新能力得到了國際認(rèn)可。國內(nèi)豐富的應(yīng)用場景,也讓大模型產(chǎn)業(yè)落地走在世界前列,無論是智慧城市、智能制造,還是醫(yī)療健康、金融科技等領(lǐng)域都在探索利用大模型技術(shù)實現(xiàn)降本增效。
以智譜AI為例,在商業(yè)領(lǐng)域前已經(jīng)有超過2000家生態(tài)合作伙伴,1000家規(guī)模化應(yīng)用和200 家深度共創(chuàng)客戶。智譜清言作為一款免費的AI工具,為大眾用戶提供了一個接觸和體驗生成式AI的窗口。
未來,隨著技術(shù)的日益成熟和應(yīng)用領(lǐng)域的不斷拓寬,我們滿懷信心地期待,我國大模型行業(yè)將不斷砥礪前行,在探索新的技術(shù)高峰的同時,享受到人工智能技術(shù)帶來的便捷與美好。