
在人工智能領域,大模型因其在理解和生成自然語言方面的卓越能力而備受關注。通過捕捉和再現人類語言的復雜性和微妙性,為使用者提供了與機器進行自然對話的可能性。
不過,這些模型背后的訓練過程卻因其成本之高而備受爭議,這不僅涉及巨額的資金投入,還包括了龐大的計算資源和時間消耗。并且,有研究指出,訓練一個先進的模型可能需要數周時間,并且需要數千甚至數萬個GPU的并行計算。加之昂貴的硬件支持,僅高性能GPU和其他專用硬件的成本可能就高達數十萬甚至數百萬美元。種規模的計算資源對于大多數研究機構和個人來說是難以承受的。
這種資源密集型的發展趨勢導致了資源獲取的不平等。大型科技公司由于其雄厚的資本和資源,能夠更容易地獲取和維護這些高性能計算資源。相比之下,小型研究機構和個人由于資金和資源的限制,往往難以參與到大模型的研究和開發中。因此,如何降低大模型的資源門檻,使其更加普及和可持續,成為當前研究和實踐中的一個重要議題。
近日,MIT、普林斯頓等研究機構的全華班團隊帶來意向全新的解決方案——JetMoE-8B,該模型使用不到10萬美元的預算完成了訓練,并且包括了1.25萬億個token和30,000個H100 GPU小時。
多管齊下,成本效益原地起飛
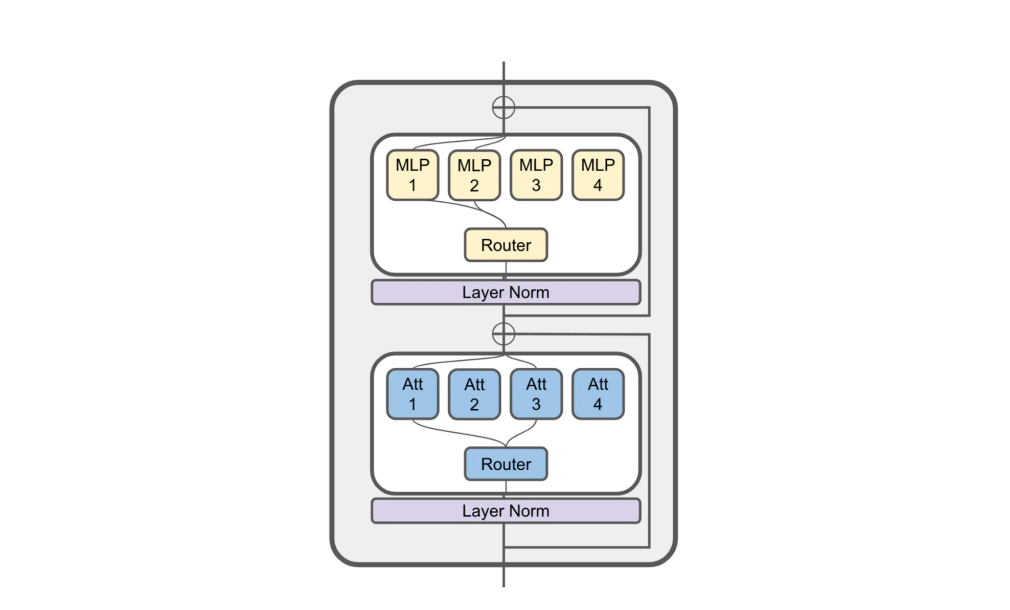
JetMoE-8B的核心特性在于其采用了Sparsely-gated Mixture-of-Experts (SMoE)架構。這種架構通過稀疏激活機制,使得模型在處理輸入時只激活必要的參數,從而大幅降低了計算成本。據了解,JetMoE-8B擁有80億個參數,但在推理時只為每個輸入令牌激活20億個參數,這使得模型在保持性能的同時,將計算成本減少了約70%。
此外,JetMoE-8B的訓練策略也頗具創新。JetMoE-8B的訓練遵循了一個兩階段策略,包括使用大規模開源預訓練數據集的1萬億個token進行訓練,以及使用指數學習率衰減進行第二階段訓練。
其中:
第一階段:預訓練
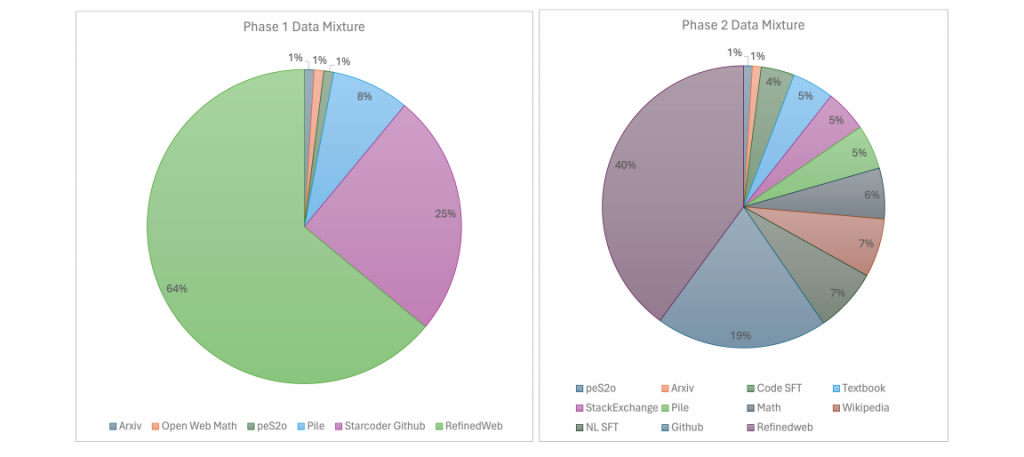
在預訓練階段,JetMoE-8B使用了來自多個高質量開源數據集的1萬億(1.25T)個token。這些數據集包括了從CommonCrawl中提取并通過MacroData Refinement (MDR) 管道處理的RefinedWeb數據集、StarCoder訓練數據、Dolma大型英文文本語料庫、The Pile以及其他數學和編程相關的數據集。這些數據集為模型提供了豐富多樣的語言和知識背景,有助于模型學習到更廣泛的語言模式和知識。
第二階段:學習率衰減
在第二階段,模型的訓練采用了指數學習率衰減策略。這意味著隨著訓練的進行,模型的學習率會按照一定的指數函數進行調整,從而逐漸減小。這種策略有助于在訓練初期快速學習并調整模型的權重,而在訓練后期則通過減小學習率來細化模型的參數,使得模型能夠更穩定地收斂到最優解。
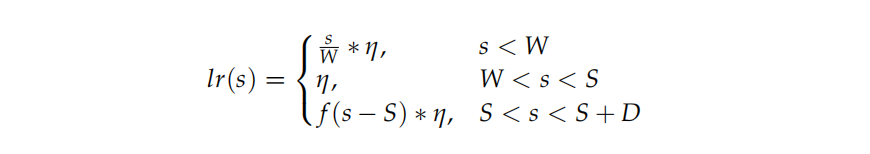
具體來說,JetMoE-8B模型使用了Warmup-Stable-Decay (WSD) 學習率調度器,這個調度器將訓練過程分為三個階段:預熱階段(warmup stage)、穩定訓練階段(stable training stage)和衰減階段(annealing stage)。在預熱階段,學習率會逐漸增加至最大值,以幫助模型快速適應訓練數據。在穩定階段,學習率保持不變,以便模型在較高水平上進行學習。最后,在衰減階段,學習率會根據預定的指數函數進行衰減,以便模型在訓練的后期進行細致的權重調整。
此外,研發團隊針對JetMoE-8B模型使用了96個NVIDIA H100 GPU組成的集群進行訓練。H100 GPU是專為AI和深度學習任務設計的高性能計算卡,具有強大的并行處理能力。通過將這些GPU組合成一個集群,JetMoE-8B能夠同時處理大量的數據和計算任務,從而加快訓練速度。
JetMoE-8B的另一個顯著特點是其開放性和易訪問性通過公開的數據集和開源的訓練代碼,使得任何有興趣的研究者都能夠訪問和使用這個模型。這種開放性不僅促進了知識的共享,也為未來的研究和合作提供了基礎。
得益于其高效的模型架構、精心挑選的數據集、兩階段訓練策略以及強大的計算資源和開源社區的支持。這些因素共同使得JetMoE-8B能夠在兩周內完成訓練,為控制成本帶來新的思路和方向。這同樣降低了進入大模型研究領域的門檻,使得更多的研究機構和個人能夠參與到這一領域的研究中來。
“卷”大小的時代已經過去,滿足需求才是王道
作為一款參數量較小的模型,JetMoE-8B充分發揮其高效率和速度優勢,為技術創新提供了強有力的支持。開發者可以在有限的資源下,快速迭代和測試新的想法,這不僅加速了新技術的研發進程,也為市場上的創新應用提供了更多可能性。小型企業和初創公司尤其受益于這種成本效益高的研發環境,它們能夠以更低的風險和成本,探索和實現自己的創新理念。
在大模型主導的市場趨勢下,參數規模并非衡量模型價值的唯一標準。實際上,隨著物聯網設備的廣泛部署,對于能夠在資源受限環境中高效運行的小參數量模型的需求日益增長。這些設備往往對計算能力和存儲空間有著嚴格的限制,而小參數量模型恰好能夠滿足這些條件,實現快速響應和實時數據處理的能力。

據了解,Meta已經在去年底推出了Llama 2模型的小型版本Llama 2 7B。此外,谷歌也在二月份推出了Gemma系列模型,法國AI公司Mistral也推出了Mistral 7B模型。
針對特定應用場景的定制化小參數量模型,正在成為研究和開發的新趨勢。研究者們專注于為特定任務量身定制輕量級模型,這些模型在保持高效能的同時,還能夠針對自然語言處理、圖像識別等特定領域進行優化。這種針對性的設計,不僅提升了模型的性能,也使得它們能夠更好地適應多樣化的應用需求。
值得注意的是,小參數量模型不僅在技術創新領域掀起了波瀾,更在商業模式和市場策略上引發的深刻變革。對于中小企業,通過使用這些模型來增強自身的產品和服務,而無需投入巨額的資金。這種成本效益高的解決方案,使得其商業應用變得更加廣泛和多樣化。
在市場策略方面,小模型的推出也反映了企業對消費者需求的深刻理解。隨著消費者對人工智能技術的理解和接受程度不斷提高,開始尋求更加實用、經濟的AI解決方案。而小模型正好滿足了這一需求,在保持性能的同時,提供了更加經濟實惠的選擇。
大模型之家認為,AI技術正在變得更加普及和可訪問,同時也意味著AI的應用范圍正在不斷擴大。隨著技術的進步和模型的優化,未來將會有更多的輕巧、高效模型出現在市場上,為用戶提供更多的選擇和便利。