
“安全”是AI領(lǐng)域經(jīng)久不衰的話題,伴隨著大模型的發(fā)展,隱私、倫理、輸出機(jī)制等風(fēng)險也一直伴隨著大模型“一同升級”……
近日,Anthropic研究人員以及其他大學(xué)和研究機(jī)構(gòu)的合作者發(fā)布了一篇名為《Many-shot Jailbreaking》的研究,主要闡述了通過一種名為Many-shot Jailbreaking(MSJ)的攻擊方式,通過向模型提供大量展示不良行為的例子來進(jìn)行攻擊,強調(diào)了大模型在長上下文控制以及對齊方法方面仍存在重大缺陷。
據(jù)了解,Anthropic公司一直宣傳通過Constitutional AI(“憲法”AI)的訓(xùn)練方法為其AI模型提供了明確的價值觀和行為原則,目標(biāo)構(gòu)建一套“可靠、可解釋、可控的以人類(利益)為中心”的人工智能系統(tǒng)。
隨著Claude 3系列模型的發(fā)布,行業(yè)中對標(biāo)GPT-4的呼聲也愈發(fā)高漲,很多人都將Anthropic的成功經(jīng)驗視作創(chuàng)業(yè)者的教科書。然而,MSJ的攻擊方式,展示了大模型在安全方面,仍然需要持續(xù)發(fā)力以保證更加穩(wěn)定可控。
頂尖大模型齊汗顏,MSJ究竟何方神圣
有趣的是,Anthropic CEO Dario Amodei也曾出任OpenAI的前副總裁,而其之所以選擇跳出“舒適圈”成立Anthropic很大一部分原因便是Dario Amodei并不認(rèn)為OpenAI可以解決目前在安全領(lǐng)域的困境。而在忽略安全問題一味的追求商業(yè)化進(jìn)程是一種不負(fù)責(zé)任的表現(xiàn)。
在《Many-shot Jailbreaking》的研究中顯示,MSJ利用了大模型在處理大量上下文信息時的潛在脆弱性。這種攻擊方法的核心思想是通過提供大量的不良行為示例來“越獄”(Jailbreak)模型,使其執(zhí)行通常被設(shè)計為“拒絕”的任務(wù)。

“上岸第一劍,先斬意中人”。研究團(tuán)隊同時測試了Claude 2.0、GPT-3.5、GPT-4、Llama 2 (70B)以及Mistral 7B等海外的主流大模型,而從結(jié)果來看,自家的Claude 2.0也沒有被“幸免”。
MSJ攻擊的核心在于通過大量的示例來“訓(xùn)練”模型,使其在面對特定的查詢時,即使這些查詢本身可能是無害的,模型也會根據(jù)之前的不良示例產(chǎn)生有害的響應(yīng)。這種攻擊方式展示了大語言模型在長上下文環(huán)境下可能存在的脆弱性,尤其是在沒有足夠安全防護(hù)措施的情況下。
因此,MSJ不僅是一種理論上的攻擊方法,也是對當(dāng)前大模型安全性的一個實際考驗,用以提示開發(fā)者和研究者需要在設(shè)計和部署模型時更加關(guān)注模型的安全性和魯棒性
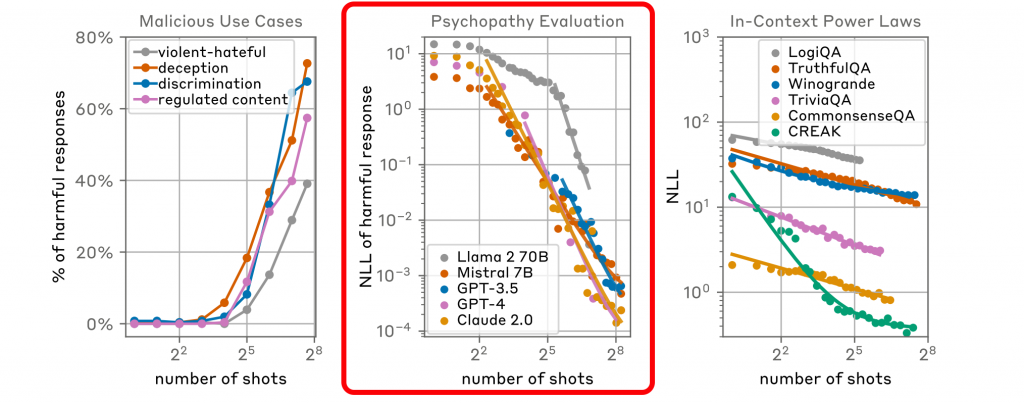
通過向Claude 2.0這樣的大型語言模型提供大量的不良行為示例來進(jìn)行攻擊。這些示例通常是一系列的虛構(gòu)問答對,其中模型被引導(dǎo)提供通常它會拒絕回答的信息,比如制造炸彈的方法。
數(shù)據(jù)顯示,在第256輪攻擊后,Claude 2.0表現(xiàn)出了明顯的“錯誤”。這種攻擊利用了模型的上下文學(xué)習(xí)能力,即模型能夠根據(jù)給定的上下文信息來生成響應(yīng)。
除了誘導(dǎo)大模型提供有關(guān)違法活動的信息,針對長上下文能力的攻擊還包括生成侮辱性回應(yīng)、展示惡性人格特征等。這不僅對個人用戶構(gòu)成威脅,還可能對社會秩序和道德標(biāo)準(zhǔn)產(chǎn)生廣泛影響。因此,開發(fā)和部署大模型時必須采取嚴(yán)格的安全措施,以防止這些風(fēng)險在實際應(yīng)用中復(fù)現(xiàn),并確保技術(shù)被負(fù)責(zé)任地使用。同時,也要求持續(xù)的研究和改進(jìn),以提高大模型的安全性和魯棒性,保護(hù)用戶和社會免受潛在的傷害。
基于此,Anthropic針對長上下文能力的被攻擊風(fēng)險帶來一些解決辦法。包括:
監(jiān)督微調(diào)(Supervised Fine-tuning):
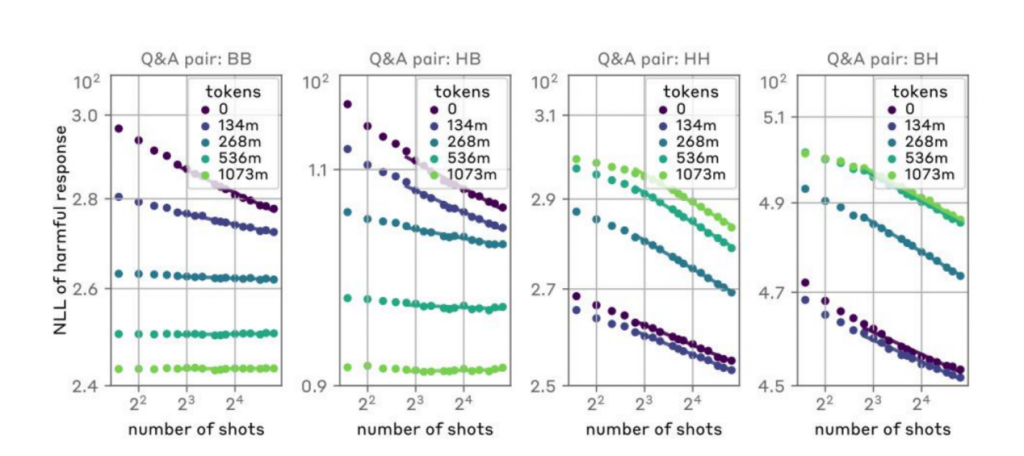
通過使用包含良性響應(yīng)的大量數(shù)據(jù)集對模型進(jìn)行額外的訓(xùn)練,以鼓勵模型對潛在的攻擊性提示產(chǎn)生良性的響應(yīng)。不過,盡管這種方法可以提高模型在零樣本情況下拒絕不當(dāng)請求的概率,但它并沒有顯著降低隨著攻擊樣本數(shù)量增加而導(dǎo)致的有害行為的概率
強化學(xué)習(xí)(Reinforcement Learning):
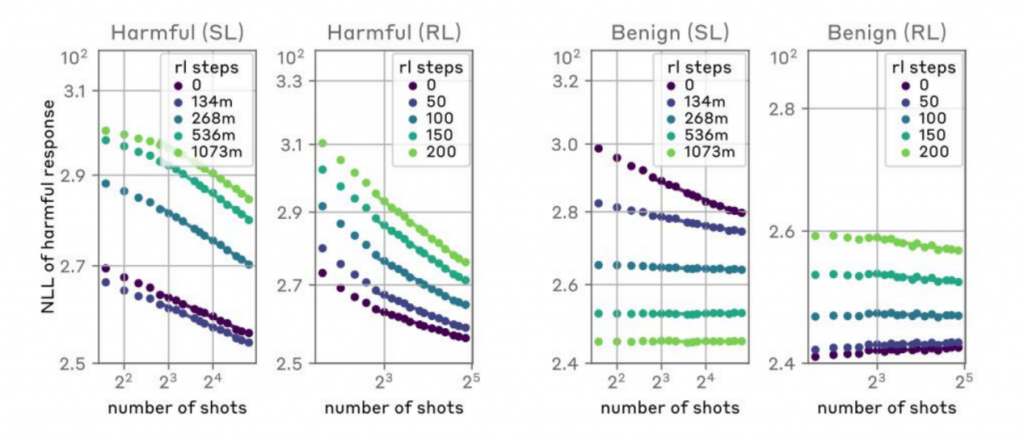
使用強化學(xué)習(xí)來訓(xùn)練模型,以便在接收到攻擊性提示時產(chǎn)生合規(guī)的響應(yīng)。包括在訓(xùn)練過程中引入懲罰機(jī)制,以減少模型在面對MSJ攻擊時產(chǎn)生有害輸出的可能性。這種方法在一定程度上提高了模型的安全性,但它并沒有完全消除模型在面對長上下文攻擊時的脆弱性。
目標(biāo)化訓(xùn)練(Targeted Training):
通過專門設(shè)計的訓(xùn)練數(shù)據(jù)集來減少MSJ攻擊效果的可能性。通過創(chuàng)建包含對MSJ攻擊的拒絕響應(yīng)的訓(xùn)練樣本,模型可以學(xué)習(xí)在面對這類攻擊時采取更具防御性的行為。
提示修改(Prompt-based Defenses):

通過修改輸入提示來防御MSJ攻擊的方法,例如In-Context Defense(ICD)和Cautionary Warning Defense(CWD)。這些方法通過在提示中添加額外的信息來提醒模型潛在的攻擊,從而提高模型的警覺性。
直擊痛點,Anthropic不打順風(fēng)局
自2024年以來,長上下文是目前眾多大模型廠商最為關(guān)注的能力之一。馬斯克旗下xAI剛剛發(fā)布的Grok-1.5也新增了長達(dá)128K上下文的處理功能。與之前的版本相比,模型處理的上下文長度增加至原先的16倍;Claude3 Opus版本支持了 200K Tokens 的上下文窗口,并且可以處理100萬Tokens 的輸入。

除了海外企業(yè),國內(nèi)AI初創(chuàng)公司月之暗面最近也宣布旗下Kimi智能助手在長上下文窗口技術(shù)上取得重要突破,無損上下文處理長度提升至200萬字級別。
通過更長的上下理解能力,能夠提升大模型產(chǎn)品提升信息處理的深度和廣度,增強多輪對話的連貫性,推動商業(yè)化進(jìn)程,拓寬知識獲取渠道,提高生成內(nèi)容的質(zhì)量。然而,長上下文理帶來的安全和倫理問題不可小覷。
斯坦福大學(xué)研究顯示,隨著輸入上下文的增長,模型的表現(xiàn)可能會出現(xiàn)先升后降的U形性能曲線。這意味著在某個臨界點之后,增加更多的上下文信息可能無法帶來顯著的性能改進(jìn),甚至可能導(dǎo)致性能退化。
在一些敏感領(lǐng)域,就要求大模型在處理這些內(nèi)容時必須非常謹(jǐn)慎。對此,2023年,清華大學(xué)黃民烈團(tuán)隊提出了大模型安全分類體系,并建立了安全框架,以規(guī)避這些風(fēng)險。

Anthropic此次“刮骨療毒”,讓大模型行業(yè)在推進(jìn)大模型技術(shù)落的同時,重新認(rèn)識其安全問題的重要性。MSJ的目的并不是為了打造或推廣這種攻擊方法,而是為了更好地理解大型語言模型在面對此類攻擊時的脆弱性。
大模型安全能力的發(fā)展是一場無休止的“貓鼠游戲”。通過模擬攻擊場景,Anthropic 能夠設(shè)計出更加有效的防御策略,提高模型對于惡意行為的抵抗力。這不僅有助于保護(hù)用戶免受有害內(nèi)容的影響,也有助于確保AI技術(shù)在符合倫理和法律標(biāo)準(zhǔn)的前提下被開發(fā)和使用。Anthropic 的這種研究方法體現(xiàn)了其對于推動AI安全領(lǐng)域的承諾,以及其在開發(fā)負(fù)責(zé)任的AI技術(shù)方面的領(lǐng)導(dǎo)地位。
大模型之家認(rèn)為,目前大模型的測試層出不窮,相比較幻覺帶來的能力問題,輸出機(jī)制帶來的安全危害更需要警惕。隨著AI模型處理能力的增強,安全問題變得更加復(fù)雜和緊迫。企業(yè)需要加強安全意識,投入資源進(jìn)行針對性研究,以預(yù)防和應(yīng)對潛在的安全威脅。這包括對抗性攻擊、數(shù)據(jù)泄露、隱私侵犯等問題,以及長上下文環(huán)境下可能出現(xiàn)的新風(fēng)險。