速途網(wǎng)9月20日訊(報道:喬志斌)今日, 商湯科技與上海人工智能實驗室聯(lián)合香港中文大學(xué)和復(fù)旦大學(xué)正式推出書生·浦語大模型(InternLM)200億參數(shù)版本InternLM-20B,并在阿里云魔搭社區(qū)(ModelScope)開源首發(fā)。
同時,書生·浦語面向大模型研發(fā)與應(yīng)用的全鏈條工具鏈全線升級,與InternLM-20B一同繼續(xù)全面開放,向企業(yè)和開發(fā)者提供免費商用授權(quán)。
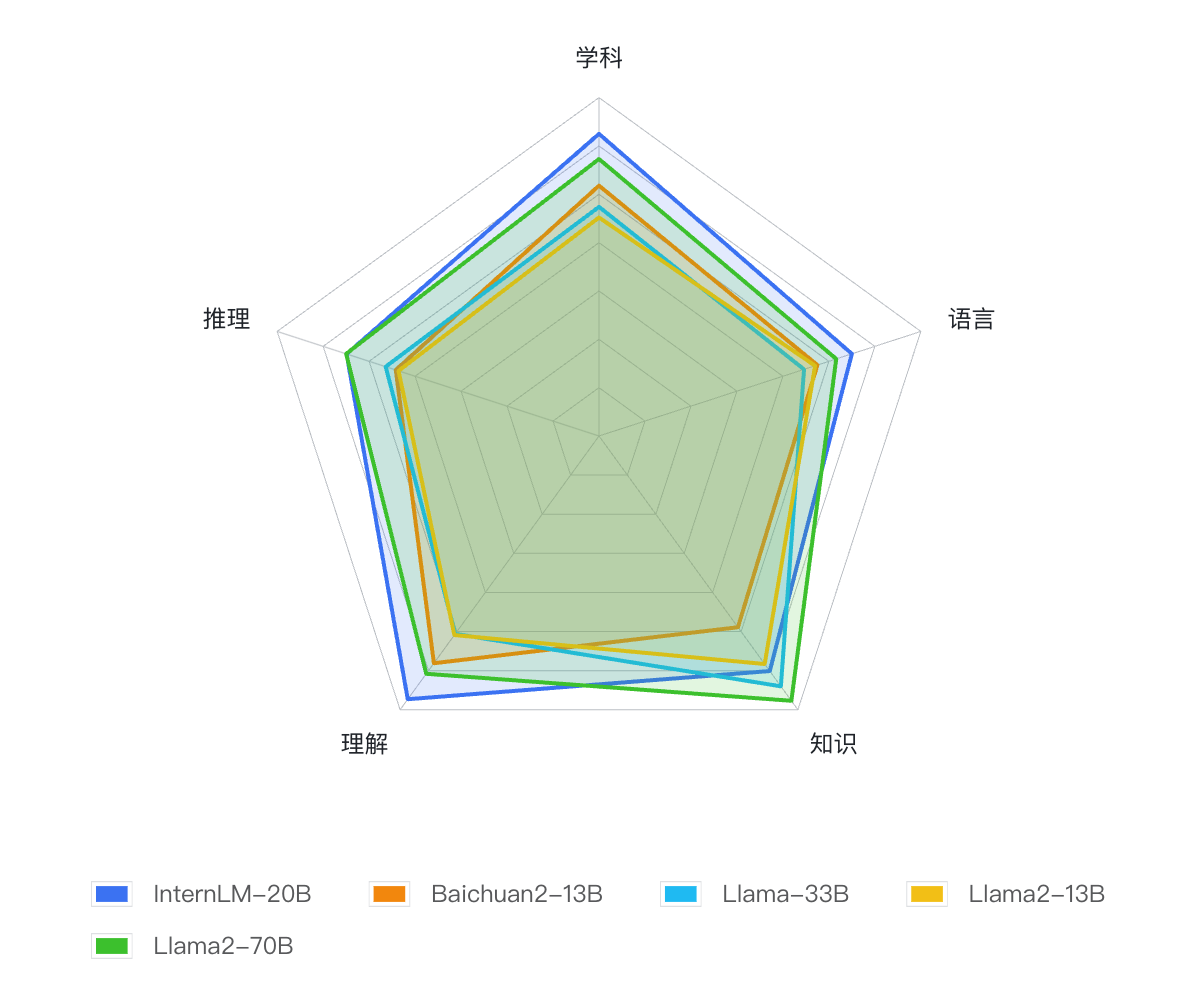
自今年6月首次發(fā)布以來,書生·浦語已經(jīng)歷多輪升級,在開源社區(qū)和產(chǎn)業(yè)界產(chǎn)生了廣泛影響。InternLM-20B模型性能先進且應(yīng)用便捷,以不足三分之一的參數(shù)量,達到了當前被視為開源模型標桿的Llama2-70B的能力水平。
代碼庫鏈接:https://github.com/InternLM/InternLM
魔搭社區(qū)鏈接:https://modelscope.cn/organization/Shanghai_AI_Laboratory

書生·浦語“增強版”:增的不只是量
相比于國內(nèi)社區(qū)之前陸續(xù)開源的7B和13B規(guī)格的模型,20B量級模型具備更為強大的綜合能力,在復(fù)雜推理和反思能力上尤為突出,因此對于實際應(yīng)用能夠帶來更有力的性能支持。
另一方面,20B量級模型可以在單卡上進行推理,經(jīng)過低比特量化后,可以運行在單塊消費級GPU上,給實際使用帶來很大的便利。
InternLM-20B是基于2.3T Tokens預(yù)訓(xùn)練語料從頭訓(xùn)練的中量級語言大模型。相較于InternLM-7B,訓(xùn)練語料經(jīng)過了更高水平的多層次清洗,補充了高知識密度和用于強化理解及推理能力的訓(xùn)練數(shù)據(jù)。
在理解能力、推理能力、數(shù)學(xué)能力、編程能力等考驗語言模型技術(shù)水平的方面,InternLM-20B與此前已開源模型相比,性能顯著增強:優(yōu)異的綜合性能,通過更高水平的數(shù)據(jù)清洗和高知識密度的數(shù)據(jù)補充,以及更優(yōu)的模型架構(gòu)設(shè)計和訓(xùn)練,顯著提升了模型的理解、推理、數(shù)學(xué)與編程能力。
InternLM-20B全面領(lǐng)先量級相近的開源模型,使之以不足三分之一的參數(shù)量,評測成績達到了被視為開源模型的標桿Llama2-70B水平。
- 擁有強大的工具調(diào)用能力,實現(xiàn)大模型與現(xiàn)實場景的有效連接,并具備代碼解釋和反思修正能力,為智能體(Agent)的構(gòu)建提供了良好的技術(shù)基礎(chǔ);
- 支持更長語境,支持長度達16K的語境窗口,更有效地支撐長文理解、長文生成和超長對話,長語境同時成為支撐在InternLM-20B之上打造智能體(Agent)的關(guān)鍵技術(shù)基礎(chǔ);
- 具備更安全的價值對齊,書生·浦語團隊對InternLM-20B進行了基于SFT(監(jiān)督微調(diào))和RLHF(基于人類反饋的強化學(xué)習(xí)方式)兩階段價值對齊以及專家紅隊的對抗訓(xùn)練,當面對帶有偏見的提問時,它能夠給出正確引導(dǎo)。
全鏈條工具體系再鞏固:各環(huán)節(jié)全面升級
今年7月,商湯科技與上海AI實驗室聯(lián)合發(fā)布書生·浦語的同時,在業(yè)內(nèi)率先開源了覆蓋數(shù)據(jù)、預(yù)訓(xùn)練、微調(diào)、部署和評測的全鏈條工具體系。
歷經(jīng)數(shù)月升級,書生·浦語全鏈條開源工具體系鞏固升級,并向全社會提供免費商用。

數(shù)據(jù)-OpenDataLab開源“書生·萬卷”預(yù)訓(xùn)練語料
書生·萬卷是開源的多模態(tài)語料庫,包含文本數(shù)據(jù)集、圖文數(shù)據(jù)集、視頻數(shù)據(jù)集三部分,數(shù)據(jù)總量超過2TB。
目前,書生·萬卷1.0已被應(yīng)用于書生·多模態(tài)、書生·浦語的訓(xùn)練,為模型性能提升起到重要作用。
預(yù)訓(xùn)練-InternLM高效預(yù)訓(xùn)練框架
除了大模型外,InternLM倉庫也開源了預(yù)訓(xùn)練框架InternLM-Train。深度整合了Transformer模型算子,使訓(xùn)練效率得到提升,并提出了獨特的Hybrid Zero技術(shù),使訓(xùn)練過程中的通信效率顯著提升,實現(xiàn)了高效率千卡并行,訓(xùn)練性能達行業(yè)領(lǐng)先水平。
微調(diào)-InternLM全參數(shù)微調(diào)、XTuner輕量級微調(diào)
InternLM支持對模型進行全參數(shù)微調(diào),支持豐富的下游應(yīng)用。同時,低成本大模型微調(diào)工具箱XTuner也在近期開源,支持多種大模型及LoRA、QLoRA等微調(diào)算法。
通過XTuner,最低僅需 8GB 顯存即可對7B模型進行低成本微調(diào),在24G顯存的消費級顯卡上就能完成20B模型的微調(diào)。
部署-LMDeploy支持十億到千億參數(shù)語言模型的高效推理
LMDeploy涵蓋了大模型的全套輕量化、推理部署和服務(wù)解決方案,支持了從十億到千億級參數(shù)的高效模型推理,在吞吐量等性能上超過FasterTransformer、vLLM和Deepspeed等社區(qū)主流開源項目。
評測-OpenCompass一站式、全方位大模型評測平臺
OpenCompass大模型評測平臺構(gòu)建了包含學(xué)科、語言、知識、理解、推理五大維度的評測體系,支持超過50個評測數(shù)據(jù)集和30萬道評測題目,支持零樣本、小樣本及思維鏈評測,是目前最全面的開源評測平臺。
自7月發(fā)布以來,受到學(xué)術(shù)界和產(chǎn)業(yè)界廣泛關(guān)注,目前已為阿里巴巴、騰訊、清華大學(xué)等數(shù)十所企業(yè)及科研機構(gòu)廣泛應(yīng)用于大模型研發(fā)。
應(yīng)用-Lagent輕量靈活的智能體框架
書生·浦語團隊同時開源了智能體框架,支持用戶快速將一個大語言模型轉(zhuǎn)變?yōu)槎喾N類型的智能體,并提供典型工具為大語言模型賦能。
Lagent集合了ReAct、AutoGPT 及ReWoo等多種類型的智能體能力,支持智能體調(diào)用大語言模型進行規(guī)劃推理和工具調(diào)用,并可在執(zhí)行中及時進行反思和自我修正。
基于書生·浦語大模型,目前已經(jīng)發(fā)展出更豐富的下游應(yīng)用,將于近期陸續(xù)向?qū)W術(shù)及產(chǎn)業(yè)界分享。
面向大模型掀起的新一輪創(chuàng)新浪潮,商湯科技堅持原創(chuàng)技術(shù)研究,通過前瞻性打造新型人工智能基礎(chǔ)設(shè)施,建立大模型及研發(fā)體系,持續(xù)推動AI創(chuàng)新和落地,引領(lǐng)人工智能進入工業(yè)化發(fā)展階段,同時賦能整個AI社區(qū)生態(tài)的繁榮發(fā)展。