尊敬的用戶:
感謝在過去的一年里對小容的期許,過去的2020年小容先后發布了3個版本的功能迭代升級,在春節來臨之際小容迎來了2020年度最后一次產品升級,內容如下:
1、新增系統內置實體
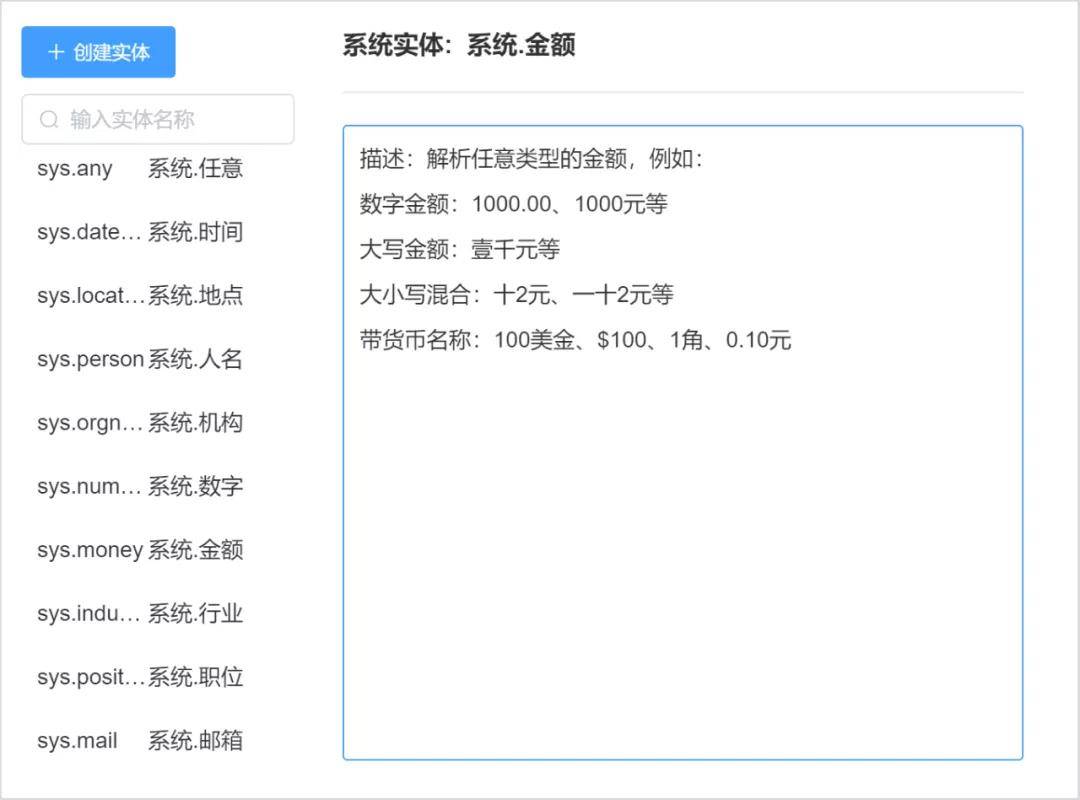
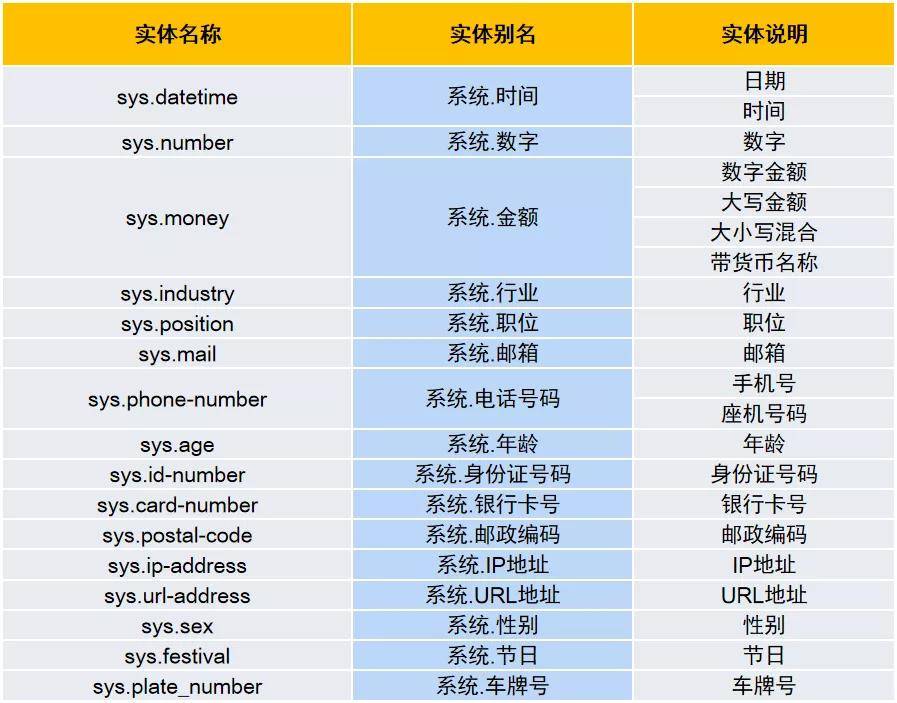
為了滿足更多業務場景中對實體信息的識別,本次更新新增了二十余種系統內置常用實體,如,數字、金額、銀行卡號、郵編、車牌號等。
2、賬號體系升級
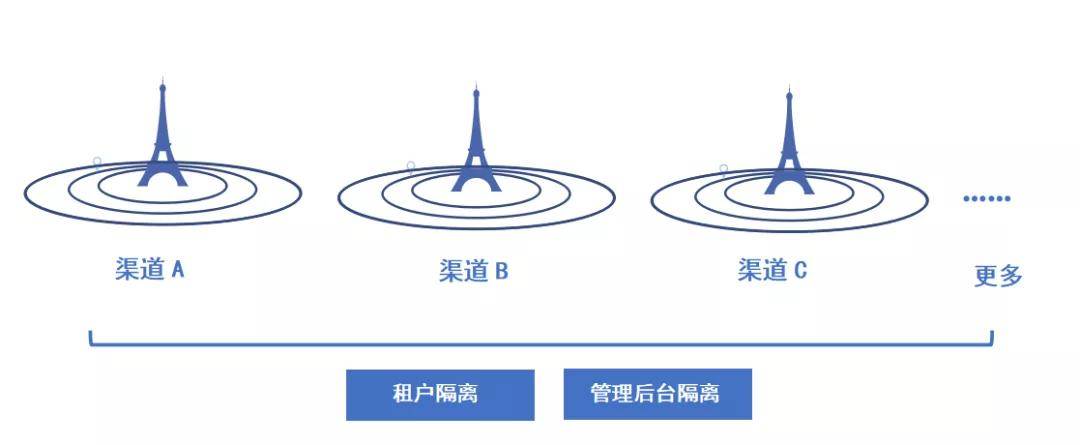
為滿足不同客群的需求,本次對系統的賬號體系進行了全面升級,在之前的多租戶賬號體系上,增加了多渠道賬號體系,實現渠道間的租戶端、管理端數據全隔離。
3、情緒識別結果輸出
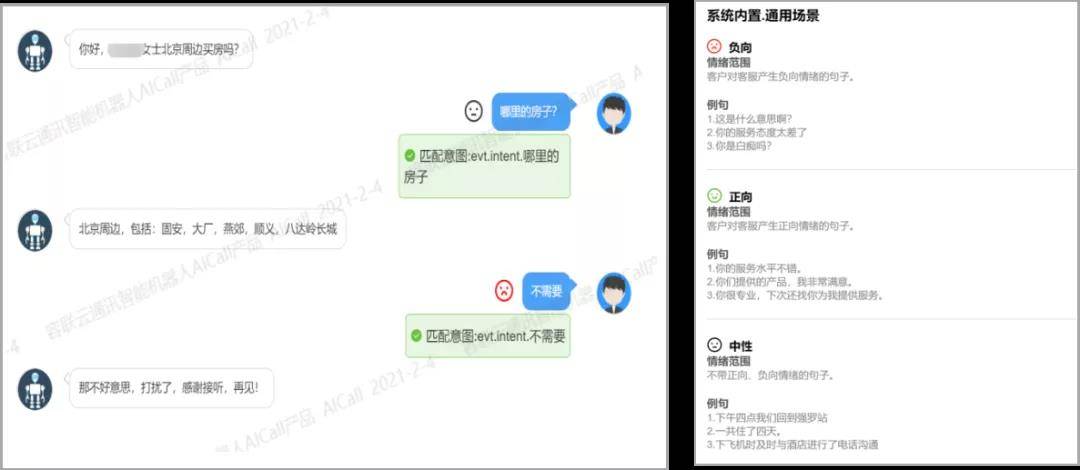
情緒識別結果輸出基于情緒引擎分析,自動檢測會話內容中文本蘊含的情緒特征,幫助企業更全面的把握產品體驗、監控客戶服務質量。
4、NLP原子能力不斷擴容

本次升級除了對產品體驗、數據安全、穩定運行等方面進行了數十項優化處理,我們也在持續不斷擴容NLP原子能力。
中文分詞
將自然語言文本切分成語義合理、完整的詞匯序列,并為每個詞匯賦予一個詞性,如:動詞、名詞、介詞等。

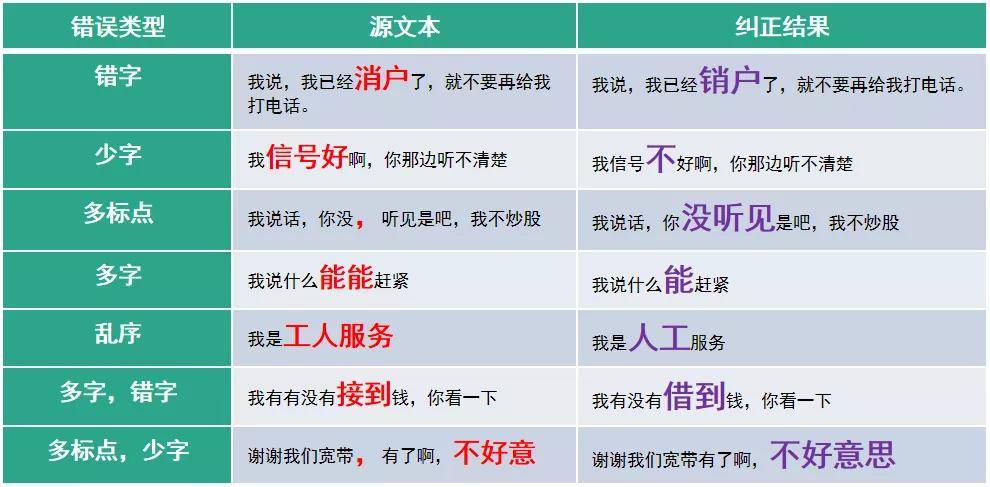
文本糾錯
自動更正文本中存在錯誤的字段,減少由此帶來的語義解析不準確或閱讀障礙。
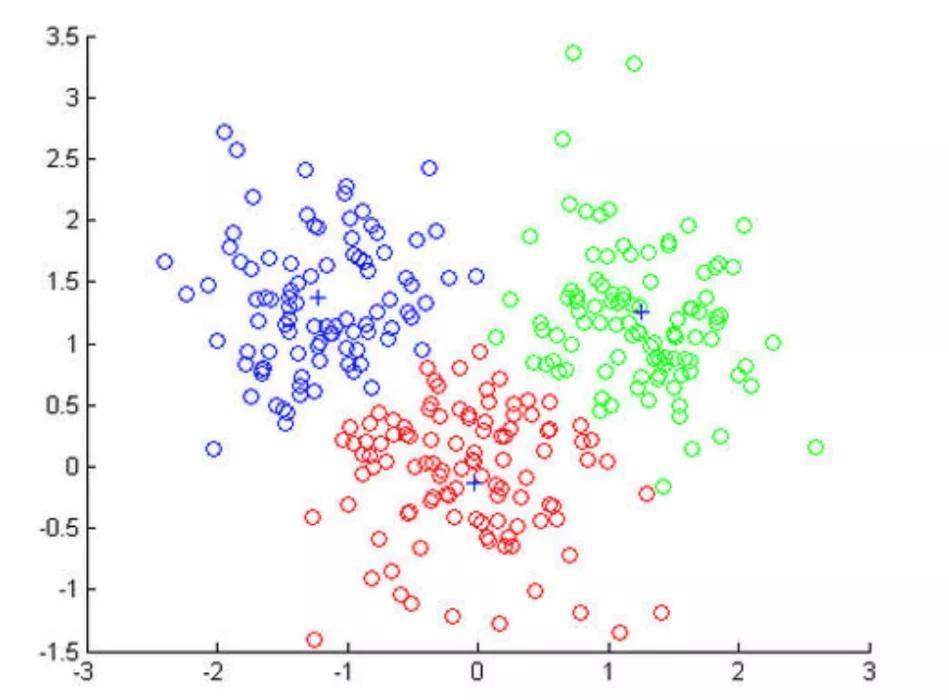
知識聚類
在沒有業務場景和標準問的情況下,通過聚類算法對無標簽數據集自動構建業務場景和標簽。協助運營人員進行數據預處理,提升數據運營效率,減輕運營人員工作量。
中心詞提取
基于BERT多任務訓練和MMR重排算法,借助積累的通用、專業詞庫對結果再處理,自動提取體現文本核心主題的關鍵詞語。

文本相似度計算
基于海量數據訓練的網絡模型,計算兩個句子之間的相似度,實現高精度語義相似度比對。文本相似度可以幫助用戶快速實現推薦、檢索、排序等應用。

句式識別
輸入對話中自然語句,返回對應的句式分類結果。支持陳述句、疑問句、感嘆句和祈使句識別。

文本摘要
基于深度語義分析模型,自動抽取文本中的關鍵信息生成簡短的文本摘要。
