化妝術,被稱作是亞洲“第四大邪術”,擁有著讓人類“改頭換面”的神奇力量。

人類世界里隨意橫行的“障眼法”,遇到人工智能后,依舊奏效嗎?阿里巴巴的圖像AI團隊就曾做過一個實驗:
他們邀請了一位仿妝達人通過化妝挑戰支付寶的刷臉閘機。精心妝扮之后,她接連成為 “赫本”“紫霞仙子”“林黛玉”,然而這三次“整容”般的化妝術在 AI 面前依然失效了—— 閘機以 100%的準確率全部成功識別。
為什么讓人類肉眼無法辨別的化妝術在AI面前就原形畢露?這是因為AI與人類之間有著完全不同的認知邏輯。
不解風情的AI,天生自帶“卸妝水”
我們都知道計算機使用二進制進行存儲和運算,計算機對圖片的理解也不例外。人類在大千世界里看到的紛紛擾擾,在計算機的眼里最后都會變成簡單的“0”和“1”。
以下面這張美女圖為例,計算機以 RGB 通道的方式理解圖片,RGB 可以表現1677萬種顏色,使得AI能夠直觀的感知圖片中的細節變化。

接著AI 會從每個像素開始去理解,不同部位之間的邊緣過度和明暗變化等特征,例如發現人的眉眼邊界,膚色明暗變換。

然后運用統計的方法對低層特征進行組合重繪,形成更高層次的特征,把人臉的某個特質部位或者整張人臉勾勒出來,最后完成快速比對。
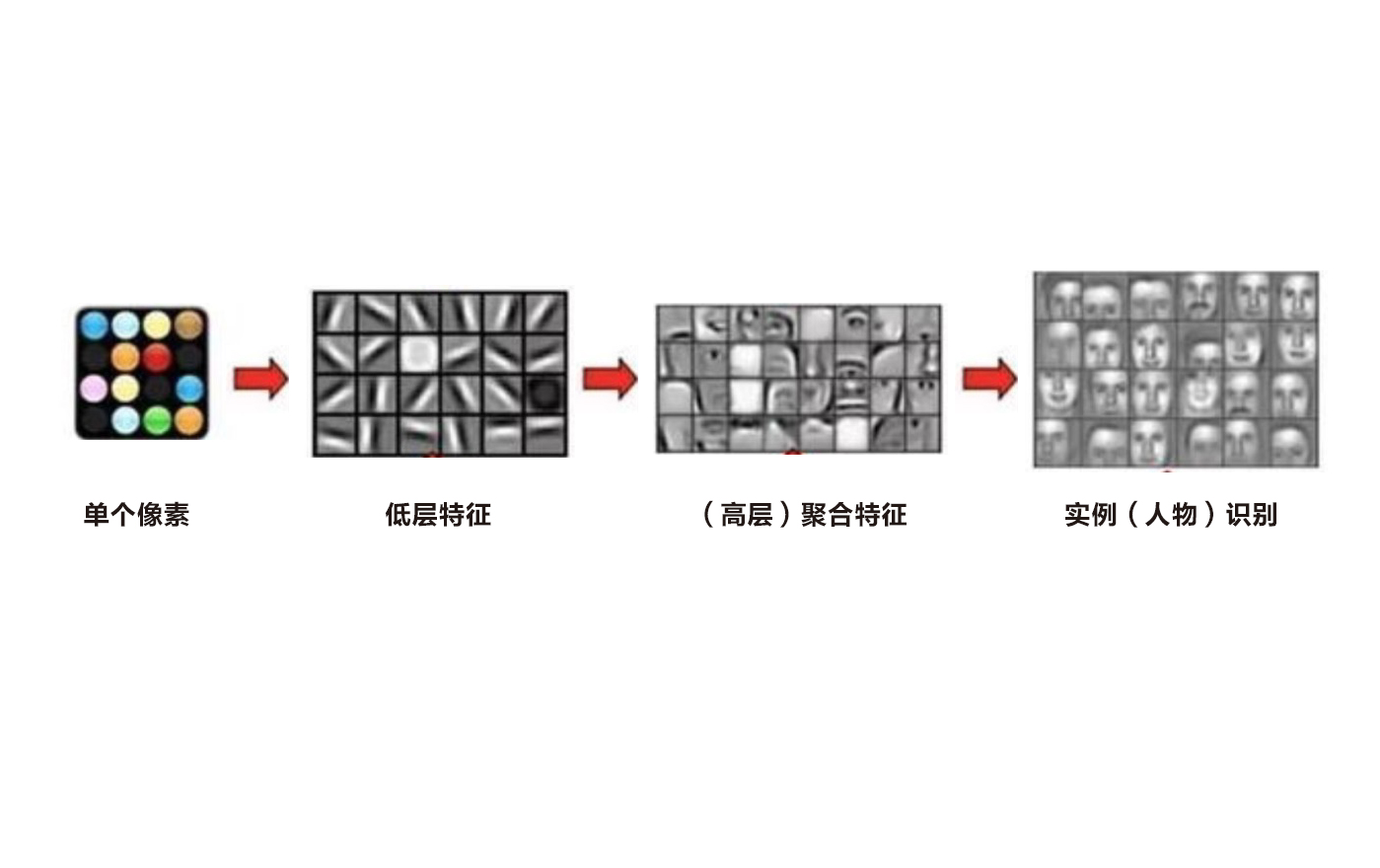
整個過程中,每一步都建立在數字的基礎上,每一步AI都像是個“冒得感情”的數學高手。細挑的柳葉眉、性感的大波浪,含羞的咬唇妝……這些人類眼中千姿百態的美,在 AI 看來,也不過在數值大小存在差異的數字而已。

兩張圖的比對,顏值爆表的女神和相貌平平的路人,最終AI這里并不會有太大區別
而“化妝術”本質是人類對色彩的靈活運用,并沒有改變人類臉部的關鍵特征,因而很難逃過AI 的雙眼。
這樣的一種極簡主義的表達,在人類看來不免略顯殘酷。然而就是在這樣簡單直接的理解之上,科學家們所設計的深度學習模型在識別率上才得以超越人類。
在應用領域,阿里巴巴研發的圖像AI——拍立淘,目前已經可以識別超過100萬種實體,建成了世界最大的商品圖搜系統。
也許有人會詫異,別說100萬種實體,就算是1萬種,記憶高手也很難記全,AI又是如何做到的?
秘訣在于AI有著人類難以望其項背的三大能力:
- 更廣泛的認知來源。一般來說,人類只能通過周圍環境和社交活動來獲得新的認知,而通過大規模學習標注好的數據,AI 可以識別越來越多的實體,并且 “看”得越多,AI識別得越好。
- 更細致的認知能力。除非長時間觀看,人類很難關注到單張圖片的每個細節信息。而 AI 不會錯過任何一個細節:每個像素點都會被平等地對待,每個像素點都得到相同的處理過程,每個像素點之間都會用相同的方法用于特征提取,最終形成一套可以被快速復制,支持高并發的實體識別系統。
3、更敏捷的認知迭代。AI能夠不斷根據新的數據調整自己,糾正已有偏差的參數,做到在整體所有圖片上最好的識別效果。例如阿里的圖像AI,就建成了可以支持以支持數十億圖片分類訓練的超大平臺。憑借集群化的大規模訓練,AI甚至可以做到一日之內看完普通人類數十年內看到的景象。
這樣循環往復的訓練下,AI識別的實體數就能夠超出人類的認知范圍。
用了60年,AI才學會人類與生俱來的“天賦”
AI的這種能力不是生來就有的,甚至在計算機誕生之初,都不具備視覺功能。
對人類而言,“認人”似乎是與生俱來的本能:剛出生幾天的嬰兒就能模仿父母的表情,我們可以毫不費力地從照片中找到熟悉的面孔,即便是暗淡燈光下,我們仍能認出樓梯末端的朋友;
這讓我們甚至難以意識到這是億萬年來進化而來的神奇能力:只憑極少細節就分辨彼此。
然而,計算機并沒有幾億年的演化時間教它辨別色彩、輪廓和形狀等特征。“認人識物”這項對人類而言輕而易舉的能力,對計算機而言卻是步步維艱。
世界上第一臺照相機出現在1839年,在計算機誕生的20世級40年代,照相機已經成為了一種大眾技術。但讓計算機和照相機實現真正意義上的交融,卻讓人類科學家付出了10年努力。
中間的鴻溝在于把圖片翻譯成計算機能理解的語言。直至1959年,計算機終于第一次“解碼”了來自人類世界里的圖像,美國科學家Russell研制了一臺灰度處理器,可以把圖片信息為二進制機器所理解的語言。
要讓AI真正完成認知上的超越,僅給機器裝上“眼睛”是不夠的,還要賦予AI像人類一樣的大腦。
這項工作的重大進展來自神經生物學的啟發。1981年,神經生物學家大衛·休伯爾和托斯坦·維厄瑟爾發現人類視覺系統是一個分級的結構,人工智能科學家可以仿照人類大腦的認知結構,以人造神經元作為神經細胞,用不同方式連接的神經元代替不同的視皮層區域,以此賦予AI像人類一樣的思考能力。

神經網絡的發明,推動了視覺AI在2012年完成了革命性的突破。這年,搭載神經網絡的AI ImageNet大規模視覺識別競賽(ILSVRC)上一騎絕塵,首次在識別準確率上完成了對人類的超越。
至此,人類給計算機裝上的這雙“眼睛”終于有了媲美人類認知的能力,但識別萬物只是計算機AI發展的第一階段。
對于我們人類而言,視覺不僅僅是為了看見,而是為了對看見的事物做出反應,更好地理解這個世界。因此,阿里科學家的也希望能夠賦予計算機這樣的能力。

阿里圖像AI正在加大投入對視覺對話方向的研究,這項技術需要綜合集成圖像識別、關系推理與自然語言理解三大能力。
它要求AI不僅能夠有效識別圖片里的實體以及它們之間的關系,還要推理出圖片所描述的事件內容,同時順暢與人類討論,最終推動AI擁有對真實視覺世界的理解與推斷能力。
前不久,谷歌運用1000塊TPU重建了完整果蠅大腦神經圖,整整40萬億像素,這是目前AI在神經元研究上的最新進步。
果蠅被作為試驗動物,它的大腦神經元為10萬個,而人類大腦的中的神經元多達1000億個。在人類的大腦面前,目前的AI還只像個孩子。
回顧計算機視覺技術的重要突破,都來自于人類將自身能力成功的“復制”給了AI。人類越了解自身,就越能創造出更高級的AI。最終在AI強大的進化能力下,也會幫助人類擴展出新的認知。